LoCobSS-documentation
Analyse der Fragen: Unterstützung der Redakteur*innen
Ein Großteil der Bemühungen rund um die Befragung von Bürger*innen stellt die Erhebung und Partizipation in den Mittelpunkt. Gleichzeitig sollte allerdings nicht vergessen werden, dass auch die Mitarbeiter*innen bei der Handhabung und Verarbeitung der eintreffenden Fragen unterstützt werden müssen. Wenn das Verfahren in Belgien7 als Grundlage genommen wird, sollten in Deutschland bei vergleichbarer Umsetzung um die 50.000 Inhalte durch die Bürger*innen generiert werden. Diese Inhalte müssen überprüft, freigegeben und kategorisiert werden. Wenn jeder Frage nur eine Minute Aufmerksamkeit geschenkt wird, bedeutet dies über 100 Arbeitstage nur mit der reinen Administration der Inhalte.
Gut kategorisierte und kuratierte Inhalte stellen auch gleichzeitig einen Mehrwert für die Nutzer*innen der Plattform dar. Deshalb sehen wir einen doppelten Nutzen darin, die Redakteur*innen bei ihrer Arbeit zu unterstützen. Bezüglich dieser Aufgaben haben uns die Organisator*innen anderer Beteiligungsverfahren und öffentlicher Plattformen zwei primäre Aufgaben genannt, bei denen Unterstützung besonders hilfreich wäre: Identifizieren von unangebrachten Inhalten und das Kategorisieren von Inhalten.
Im Rahmen des Vorhabens LoCobSS haben wir uns insbesondere mit Methoden der automatisierten Verarbeitung von Inhalten beschäftigt. Im Folgenden präsentieren wir die von uns prototypisch implementierten Dienste und deren Evaluation. Die technische Dokumentation befindet sich in Kapitel 5.
Testdaten
Um die folgenden Ansätze evaluieren zu können, wurden vergleichbare Testdaten benötigt. Zu diesem Zweck wurde ein Harvester entwickelt, welcher die Daten des belgischen Beteiligungsverfahrens7 aggregiert und strukturiert für dieses Vorhaben aufbereitete.
Für weitere Details siehe das Repository des Harvesters.
Hate Speech
Bevor Eingaben der Bürger*innen über die Plattform veröffentlicht werden, sollten diese dahingehend überprüft werden, ob sie den inhaltlichen Guidelines entsprechen. Beispiele für Inhalte die in diesem Schritt identifiziert und gefiltert werden sollten, sind z.B. rassistische, sexistische, obszöne oder gewaltverherlichende Inhalte. Eine große Herausforderung bei der Nutzung automatisierter Verfahren ist, dass die meisten algorithmischen Verfahren auf englischsprachigen Inhalten und Daten trainiert und optimiert sind. Insbesondere bei Thematiken wie Schimpfwörtern sind aber sprachliche Nuancen und z.B. auch spezielle Schreibweisen sehr wichtig. Hinzu kommen zweideutige Sätze, bei denen Algorithmen nur schwer die tatsächlich intendierte Bedeutung fehlerfrei zuordnen können. Entsprechend zeigte sich in den Tests auch, dass eine Menge unangebrachte Inhalte von den algorithmischen Analysemethoden nicht erkannt wurden. Deshalb kann die Identifikation von Hate Speech im aktuellen Implementationszustand nur als Hinweis an die Redakteur:innen dienen, nicht aber als automatisierter Filter eingesetzt werden.
3.2.1 Implementierte Verfahren
Um Ansätze für englische Sprache nutzen zu können, haben wir die Eingaben der Nutzer*innen automatisiert ins englische übersetzt.
- ProfanityFilter (python)
- HateSonar (python)
3.2.2 Verbesserung
Sollte man solch einen Ansatz weiterverfolgen, müsste man gute deutsche Trainingsdaten und deutsche Vokabularien generieren. Während dies ein grundsätzlich löbliches Vorhaben wäre, welches sicherlich auch anderen Entwickler*innen und Forscher*innen zu Gute käme, ist es fraglich, ob dies im Rahmen eines solchen Vorhabens finanziell angemessen und umsetzbar wäre wäre.
3.2.3 Alternativen
Die meisten großen Content-Plattformen nutzen sogenannte Micro-Job oder Micro-Task Plattformen, bei denen Personen für Kleinstaufgaben bezahlt werden. Größere Unternehmen wie z.B. Facebook haben eigene Content-Moderators, um Hate-Speech oder andere unangebrachte Inhalte zu filtern und zu löschen. Beide Methoden sind nur bedingt zu empfehlen, da Micro-Jobber*innen häufig weit unter dem Mindestlohn bezahlt werden und psychisch stark beanspruchende Arbeit leisten müssen. Diese Problematik sollte bei ähnlichen Ansätzen für die Content-Redaktion berücksichtigt werden. Empfehlenswerter wäre es, Projektstellen zu schaffen, wodurch angemessene Löhne und Arbeitsbedingungen sichergestellt werden können.
Kategorisierung
Um die eingehenden Beiträger der Bürger*innen analysieren zu können und nachnutzbar zu machen, müssen diese kategorisiert werden. Hierzu müssen aus den gesamten Inhalten übergreifende Thematiken abgeleitet werden und die Inhalte entsprechend mit Schlagworten (Tags) oder Kategorien (Taxonomien) versehen werden. Im Gegensatz zur Betrachtung und Bewertung individueller Inhalte, müssen bei diesem Aufgabe viele Inhalte gleichzeitig miteinander verglichen werden. Nach Experimenten mit verschiedenen Natural Language Processing (NLP) und Machine Learning (ML) Verfahren, haben wir uns hierbei für einen zweistufigen Prozess entschieden, der vielversprechende Ergebnisse liefert.
3.3.1 Vektorisieren von Text
Ein in der algorithmischen Textanalyse weit verbreitetes Verfahren ist das Umwandeln von Texten in Vektoren. Das Verfahren basiert darauf, dass ein künstliches Neuronales Netzwerk auf einem großen Text-Korpus trainiert wird. Stark abstrahiert dargestellt lernt das Netzwerk dabei, Strukturen und Ähnlichkeiten von Textbausteinen zu erkennen. Später kann das künstliche Neuronale Netzwerk genutzt werden, um Textbausteinen einen mehrdimensionalen Vektor zuzuordnen. Über diese Vektoren können dann z.B. Vergleiche angestellt werden, um die Ähnlichkeit von Textbausteinen festzustellen. Hierbei gibt es Verfahren die für einzelne Wörter (z.B. word2vec) optimiert sind und andere, die ganze Texte analysieren können. Wir haben für diesen Schritt den von Google Forscher*innen entwickelten Universal Sentence Encoder in Version 4 genutzt.
Zur einfachen Analyse wurde ein Service entwickelt, welcher Texte in 512-dimensionale Vektoren umwandelt.
Der Vorteil dieses Verfahrens ist, dass die Berechnung der Ähnlichkeiten sowohl mit sehr wenigen Inhalten funktioniert, als auch mit sehr vielen. So kann, schon während die ersten Inhalte eintreffen, sehr früh eine erste Analyse durchgeführt werden.
3.3.2 Ableiten von Ähnlichkeit
Aufbauend auf den Text-Vektoren lässt sich eine Distanzmatrix erstellen, um schnell Ähnlichkeiten zwischen einzelnen Texten abzuleiten. So können z.B. Content-Recommendations basiernd auf den berechneten Text-Ähnlichkeiten durchgeführt werden. Hierzu haben wir einen einfachen Service entwickelt, welcher zu einem nutzer*innengenerierten Inhalt die ähnlichsten Inhalte zurückgibt.
3.3.3 Kategorien identifizieren und Inhalte kategorisieren
Im Laufe der Entwicklung dieser Module haben wir unterschiedliche Methoden aus den Bereichen des Topic-Modellings und des Clusterings getestet. Topic-Modelling beschäftigt sich im NLP mit dem Identifizieren von übergreifenden Themen innerhalb eines Textes. Clustering Methoden wiederum versuchen ähnliche Datensätze zu identifizieren, in unserem Fall basierend auf den Werten der Vektoren.
Beide Ansätze haben keine zufriedenstellenden Ergebnisse geliefert. Deshalb haben wir das Prinzip des Clusterings genommen und daraus einen kollaborativen Ansatz entwickelt, bei welchem Nutzer*innen und Algorithmen gemeinsam versuchen, passende Gruppen zu bilden.
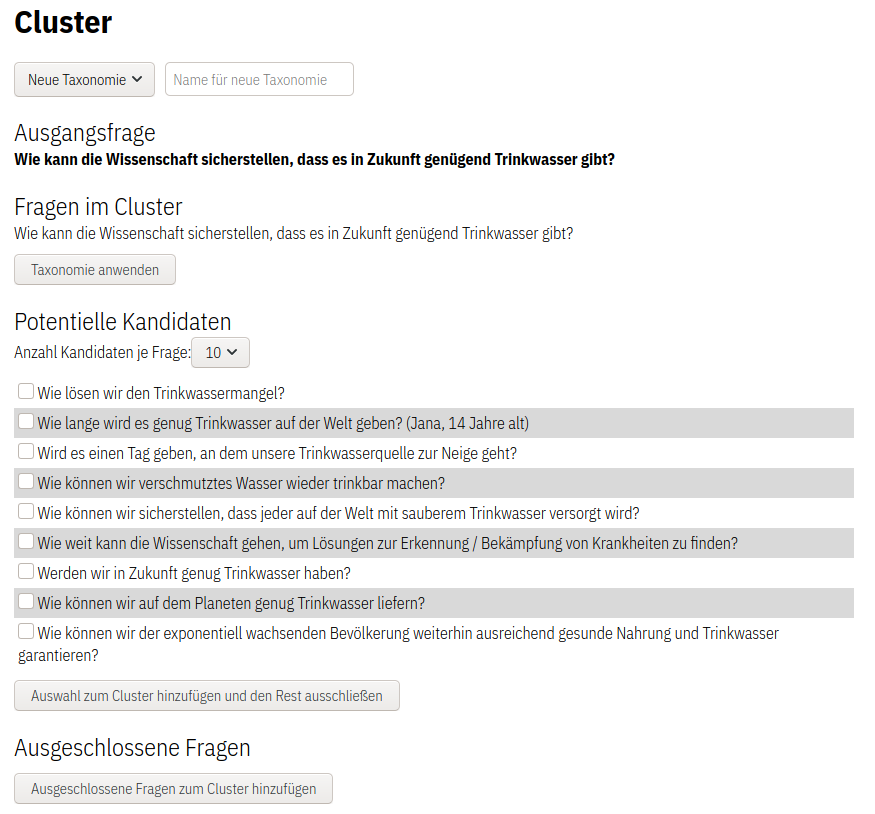
Die Redakteur*innen wählen dazu erst einen Inhalt als Ausgangspunkt aus (siehe Abbildung Ausgangsfrage). Das System sucht nun zu diesem Objekt ähnliche Inhalte heraus (siehe Abbildung Potentielle Kandidaten). Aus diesen “Ähnlichkeits-Kandidaten” können nun die tatsächlich ähnlichen Objekte ausgewählt werden. Diese werden dann dem aktuellen Cluster hinzugefügt. Alle nicht ausgewählten Kandiaten landen in der Liste ausgeschlossener Inhalte. Nachdem eine Auswahl getätigt wurde, nutzt das System die neuen Objekte, um daraus weitere ähnliche Inhalte abzuleiten. So können mit nur wenigen Clicks hunderte Objekte in Kategorien kombiniert werden. Abschließend kann man der Sammlung einen Namen geben und so die Navigation und Suche für Besucher*innen der Seite unterstützen.

Als visuelles Feature werden die Inhalte der Plattform in einer zweidimensionalen Punktewolke abgebildet. Mit Hilfe einer Dimensionsreduktion (t-SNE) werden die Vektoren auf zwei Dimensionen reduziert. In dieser Wolke wird auch die aktuelle Auswahl des Cluster angezeigt. In der aktuellen Variante ist dies nur eine statische Visualisierung der ausgewählten Inhalte, zukünftig könnte man dies dahingehend erweitern, dass die Auswahl auch über die Visualisierung durchgeführt werden kann.
3.3.4 Nutzer*innengenerierte Kategorien
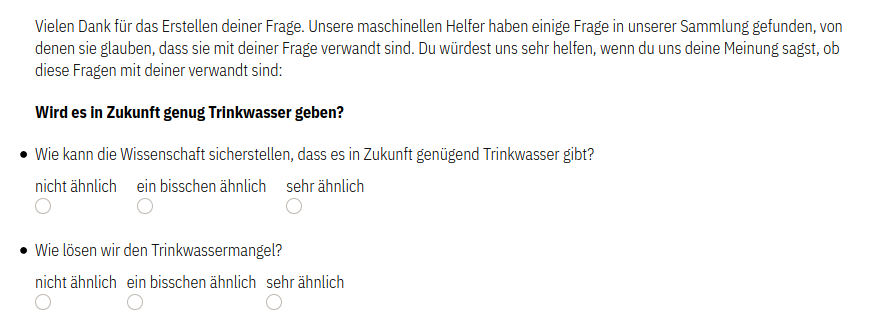
Neben der Kategorisierung durch die Redakteur*innen haben wir ein weiteres Feature implementiert, was einen crowd-sourcing Ansatz bei der Kategorisierung verfolgt. Jede*r Bürger*in die*\der einen Inhalt auf der Plattform generiert, erhält nach dem Abschicken Vorschläge verwandter Inhalte. Die Bürger*innen können dann Feedback geben, ob diese Inhalte mit ihrer Frage verwandt sind oder nicht.
Hinweis: Während die nutzer*innenseitige Kategorisierung vollständig implementiert ist, fehlt noch eine Kombination mit dem System der Redakteur*innen. Die direkte Vektorisierung des Textes dauert im aktuellen Setup etwas länger. Aus Kostengründen geht der Klassifizierungsservice automatisch in einen Ruhezustand. Das “Erwachen” aus diesem Ruhezustand benötigt etwas Zeit. Bei einer finalen Integration könnte man dieses Delay auf ein Minimum reduzieren.
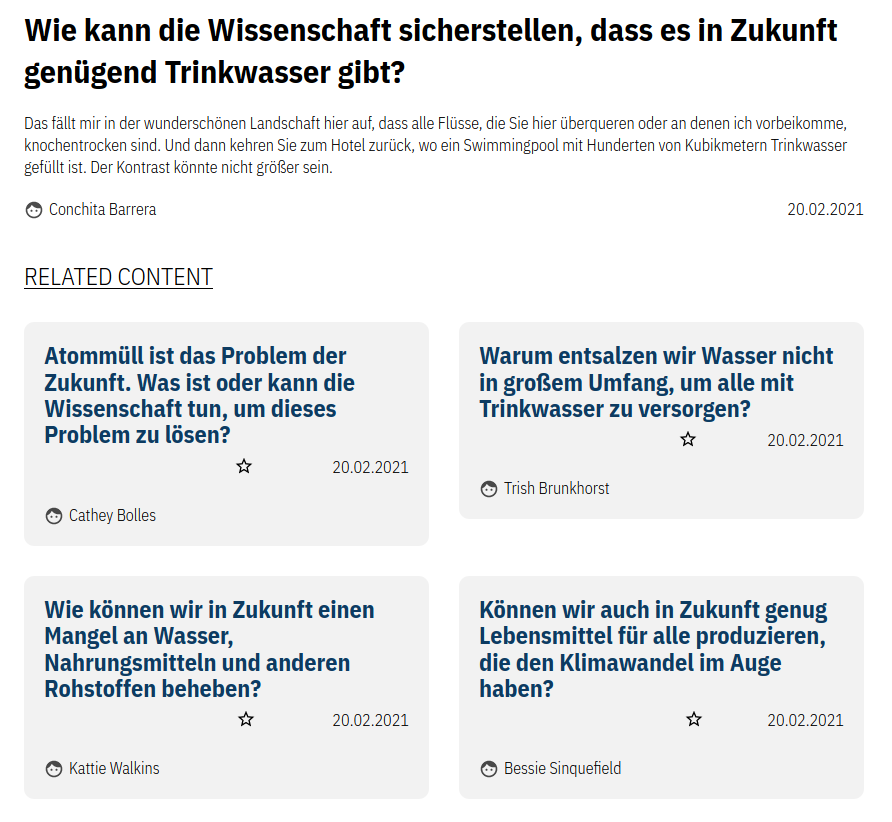
3.3.5 Content Recommendation
Ähnlich wie das Kategorisieren der Redakteur*innen, können die zugrundeliegenden Daten auch genutzt werden, um den Nutzer*innen der öffentlichen Seite Inhalte zu empfehlen. Diese Funktionalität ist bereits im aktuellen Prototypen integriert (siehe Abbildung unten). Wählt man eine Frage aus, werden ähnliche Inhalte angezeigt. Um Serendipität zu fördern, sind dies nicht nur die “ähnlichsten” Inhalte sondern auch Inhalte, die etwas weiter entfernt sind. Die Auswahl wird leicht randomisiert, sodass bei jedem Besuch andere ähnliche Inhalte angezeigt werden.
Sentiment Analysis
Auch wenn diese Funktion während unserer Recherchen nicht als eines der wichtigsten Features für eine Partizipationsplattform aufkam, haben wir die Funktion von automatisierten Sentiment Analysen im Rahmen der Entwicklung von Hate-Speech-Detection exploriert. Die Ergebnisse waren sehr durchmischt. Teils werden Einstellungen zu bestimmten Themen sehr gut erkannt, häufig werden Einstellungen aber als eher neutral vom System bewertet. Für zukünftige Entwicklungen haben wir auch hierzu einen Service entwickelt, welcher entsprechende Sentiment-Werte für einen eingegebenen Text zurückgibt.