LoCobSS-documentation
Prototyp: Technische Dokumentation
Die technische Dokumentation gliedert sich in zwei Abschnitte. Der erste Anschnitt bezieht sich auf die Umfrage-Plattform und alle dazugehörigen Komponenten und der zweite Abschnitt behandelt die beiden Prototypen zur datengestützten Wissenschaftsvermittlung. Die hier vorliegende Dokumentation gibt eine Übersicht über die verschiedenen entwickelten Komponenten. Eine detailliertere und stärker technisch fokussierte Dokumentation befindet sich in den einzelnen Code-Repositorien, welche hier verlinkt werden. Diese detaillierten technischen Dokumentationen sind in englische Sprache verfasst, um eine möglichste breite Nachnutzbarkeit der einzelnen open-source Komponenten sicherzustellen.
Obwohl sich viele der Komponenten kurz vor einem Release-State befinden, muss hier deutlich unterstrichen werden, dass es sich bei den entwickelten Prototypen nicht um Release-Candidates handelt. Ziel des Vorhabens LoCobSS war es vielmehr, Ideen und Möglichkeiten für den hier vorliegenden Anwendungsfall aufzuzeigen. Um sich hierbei möglichst realistischen Umsetzungsoptionen anzunähern und gleichzeitig erste Grundlagen für eine spätere Implementierung zu schaffen, wurden diverse Komponenten und Prototypen entwickelt. Um diese zu release-fähigen Produkten weiterzuentwickeln, sollten vor allem folgenden Punkte bearbeitet werden:
- Tests für alle Bereiche schreiben
- Continous-Deployment verfeinern und mit Tests kombinieren
- Weitere Optimierungen für mobile Endgeräte
- Frontends auf allen aktuellen Browsern testen
- Code und Implementation auf Skalierung hin optmieren
- Sicherheitsfeatures ergänzen und überprüfen
- Datenschutzbestimmung basierend auf den genutzten Komponenten erarbeiten
- Code refactoring
- In LoCobSS-Plattform: Trennen von Bürger*innen-Plattform und Verwaltungsebene in zwei Anwendungen, um den Fußabdruck zu verkleinern.
5.1 Umfrage-Plattform
5.1.1 Übersicht
In der aktuellen Version wurden die Services und Komponenten für die Google-Cloud-Infrastruktur optimiert. Die meisten Komponenten sind aber völlig plattform-unabhängig. Die einzigen Komponenten, die sich nicht ganz so leicht anpassen lassen, sind alle Komponenten rund um die Nutzer*innenverwaltung. Da selbige nicht im Fokus der prototypischen Entwicklung lagen, haben wir Googles Firebase Ökosystem genutzt, um möglichst unkompliziert eine Verwaltung von Nutzer*innen implementieren zu können.
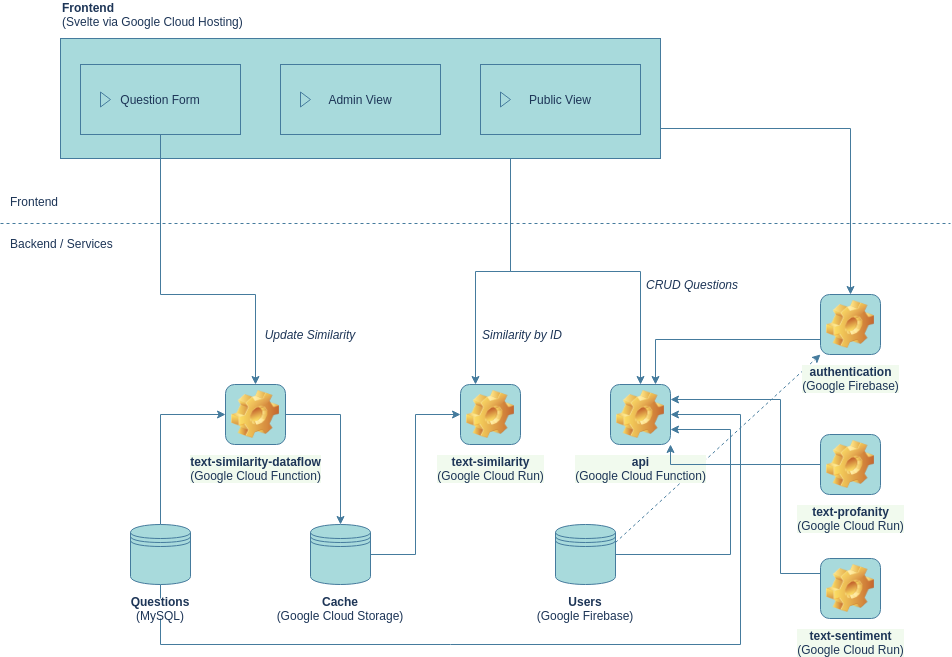
5.1.2 Frontend
Das Frontend, in der alle Komponenten für die Umfrage zusammenfließen, ist im LoCobSS-platform Repository zusammengeführt. Es handelt sich hierbei um eine sogenannte Single Page Application (SPA), welche mit dem Framework SVELTE entwickelt wurde. Die Anwendung lässt sich grob in drei Hauptbereiche unterteilen: 1) Öffentlicher Bereich zum Durchstöbern der Fragen und zum Fragen stellen, 2) Interner Bereich für Bürger*innen zur Verwaltung der eigenen Daten und zur Verfolgung von Fragen, sowie 3) der Bereich für Redakteur*innen zum Verwalten der Fragen und Nutzer*innen.
Repo: LoCobSS-platform
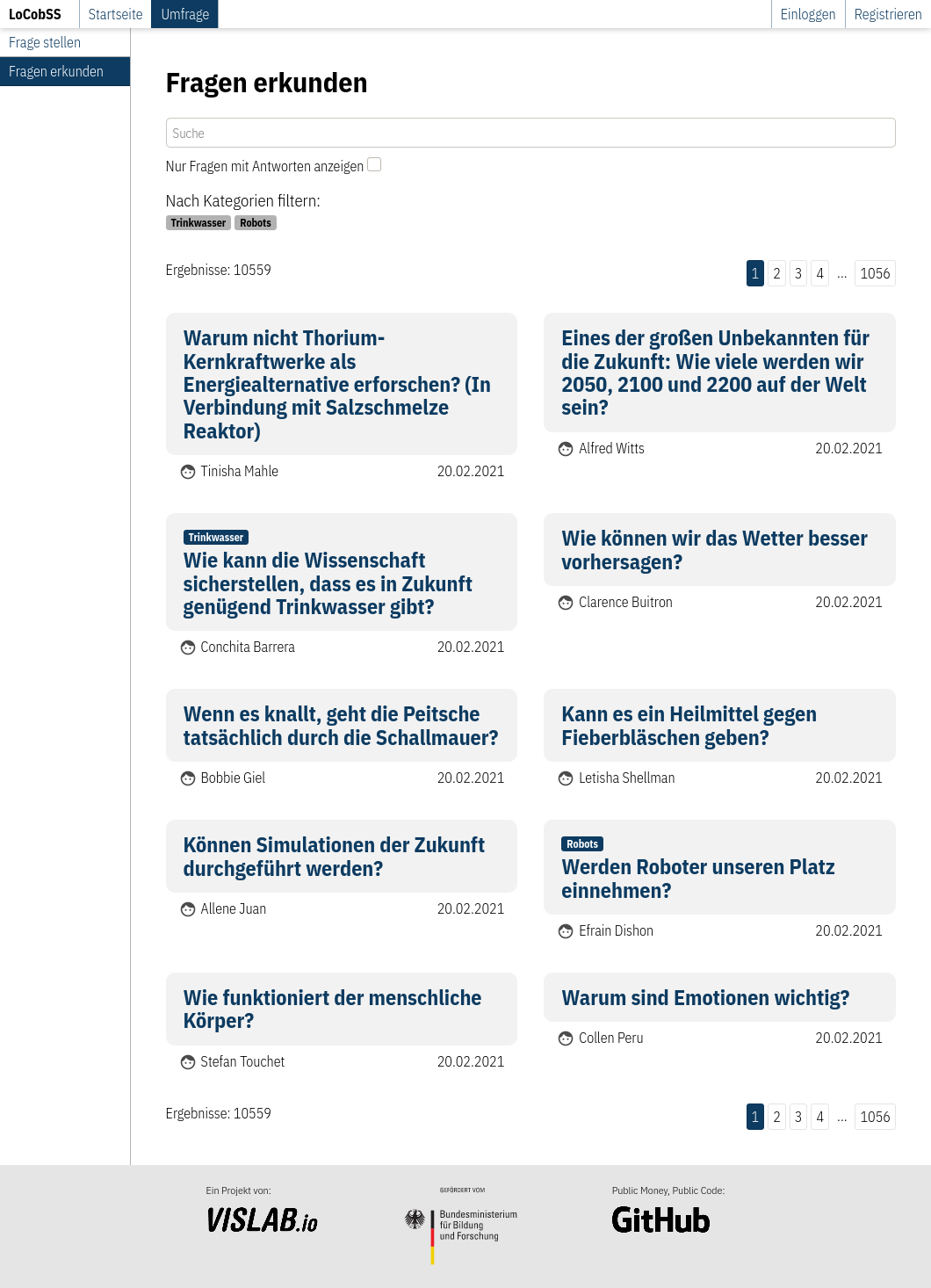
Öffentlicher Bereich
Nutzer*innen können die von anderen Teilnehmer*innen erstellten Inhalte auf der Plattform im öffentlichen Bereich explorieren. Inhalte können nach Taxonomien, Datum und Suchbegriffen gefiltert werden sowie danach, ob es schon eine Antwort für die Frage gibt. Daten werden über die API bereitgestellt.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/list.svelte
API: /public/questions
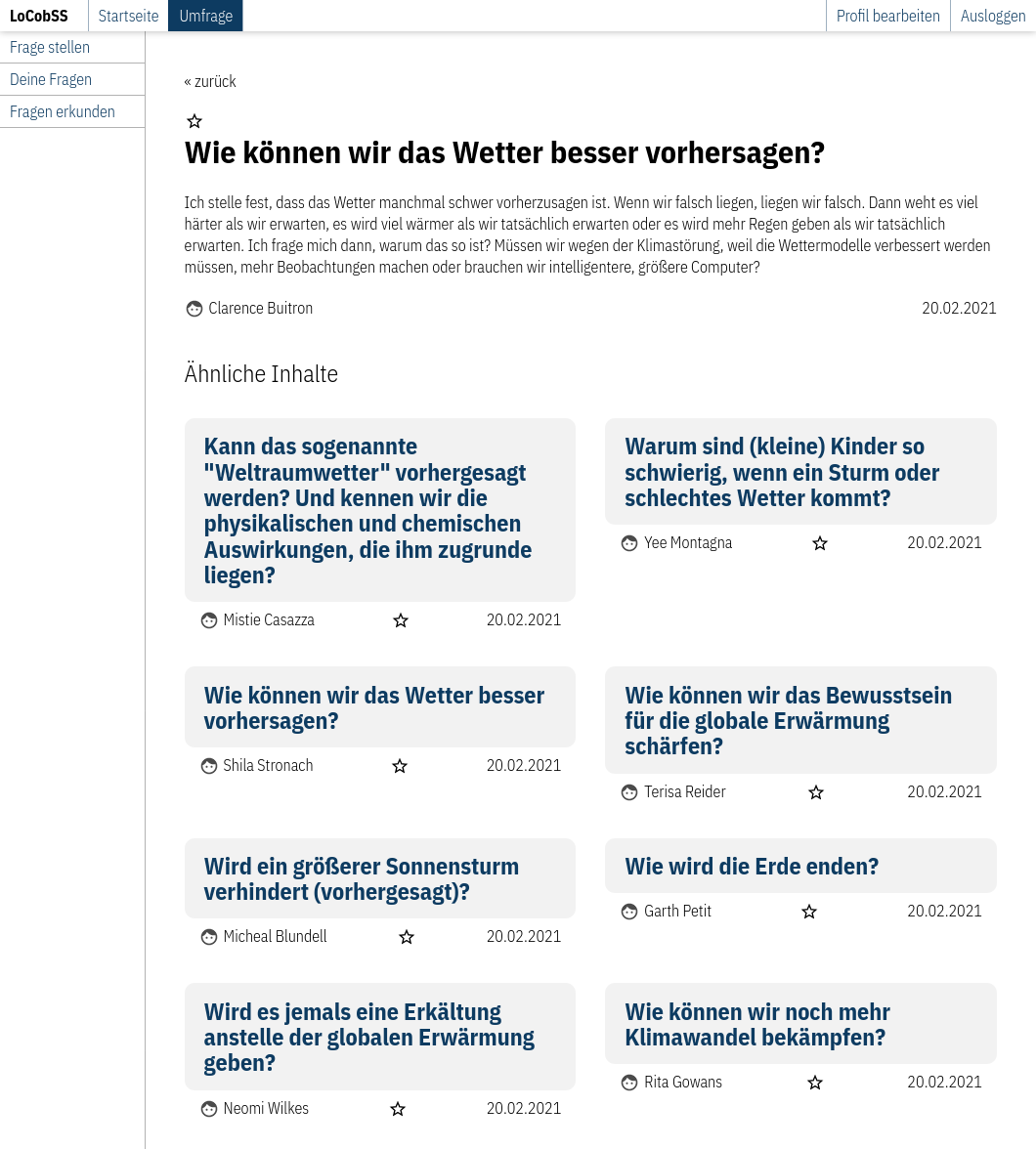
Zu jeder Frage gibt es auch eine Detailansicht. Neben weiteren Details zur Frage werden hier auch ähnliche Fragen angezeigt. Diese werden über die API abgerufen, welche dafür den similarity-Service nutzt.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/details.svelte
API: /public/questions/:id
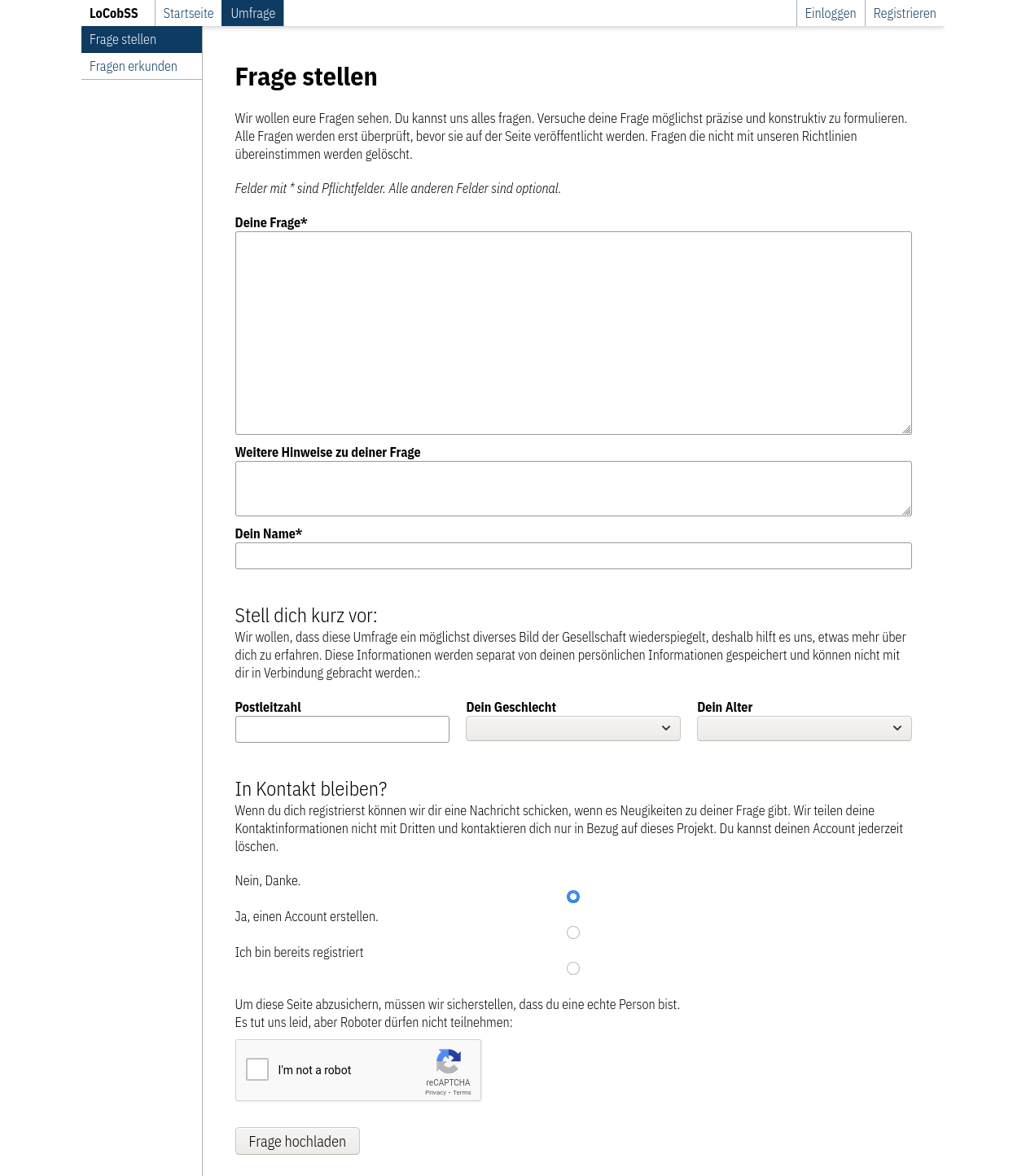
Das Formular zum Erfassen der Fragen nutzt Client-Side Classification zur Erfassung von Regiostar-5-Gebieten (siehe 2.4). Das Recaptcha-Verfahren11 schützt die Seite.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/ask.svelte
API: /question/create
Die abgeschickten Fragen werden auf Profanität hin überprüft, eine Sentiment-Analyse wird durchgeführt, sowie Ähnlichkeiten zu Beiträgen anderer Bürger*innen werden berechnet. Fragedaten und statistische Daten werden unabhängig gespeichert. Danach werden ähnliche Fragen angezeigt, welche die Benutzer*in dann ranken kann (siehe Kapitel 3.3.4).
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/ask.svelte
API: /question/link
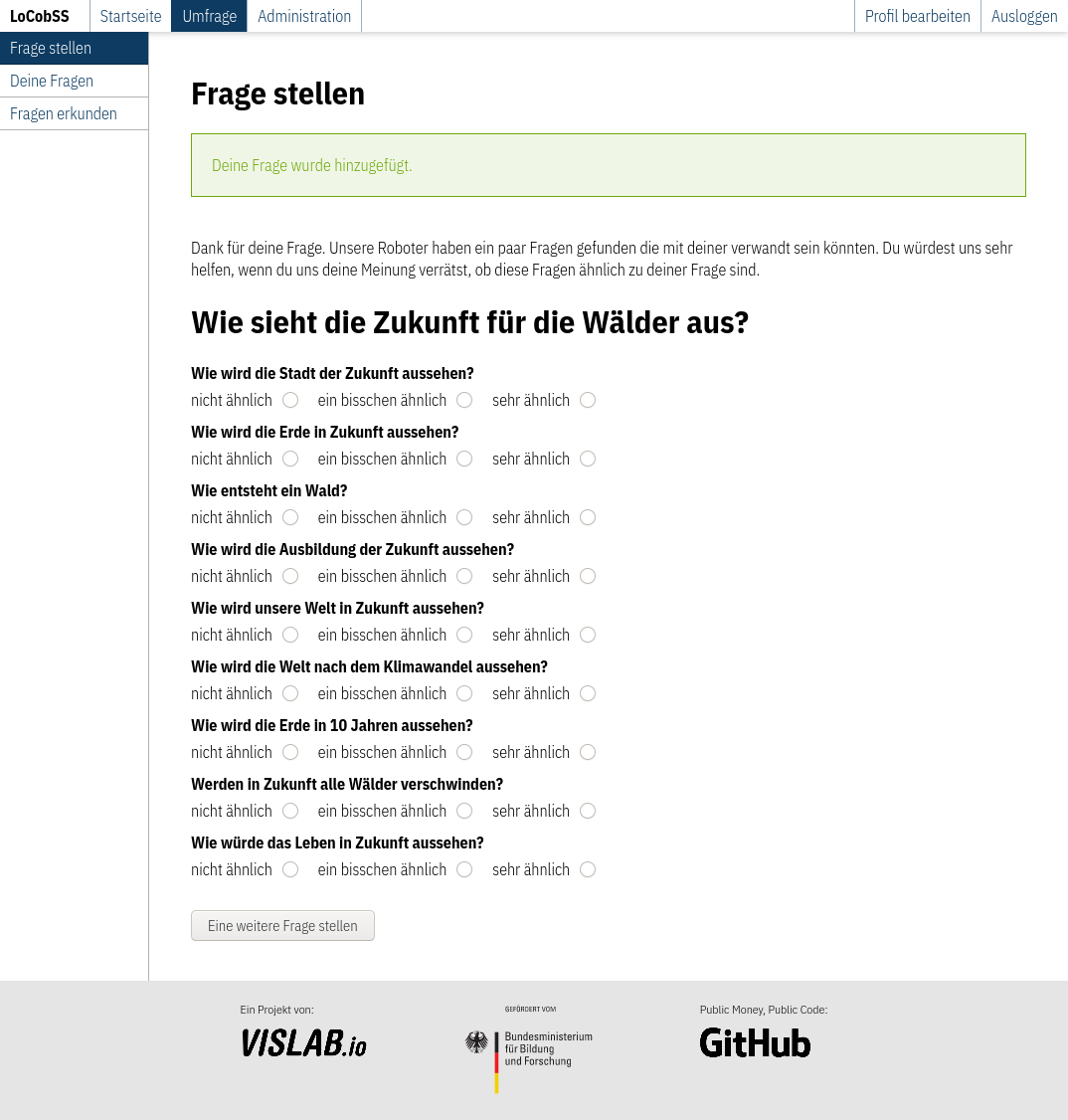
Benutzer*innen können sich registrieren, während sie eine Frage stellen, oder unabhängig davon.
Router: src/lib/routes/user.ts
View: src/views/pages/user/register.svelte
Durch den Login bekommen Nutzer*innen die Möglichkeit, Fragen zu markieren (like) und ihre eigenen Fragen zu verfolgen.
Router: src/lib/routes/user.ts
View: src/views/pages/user/login.svelte
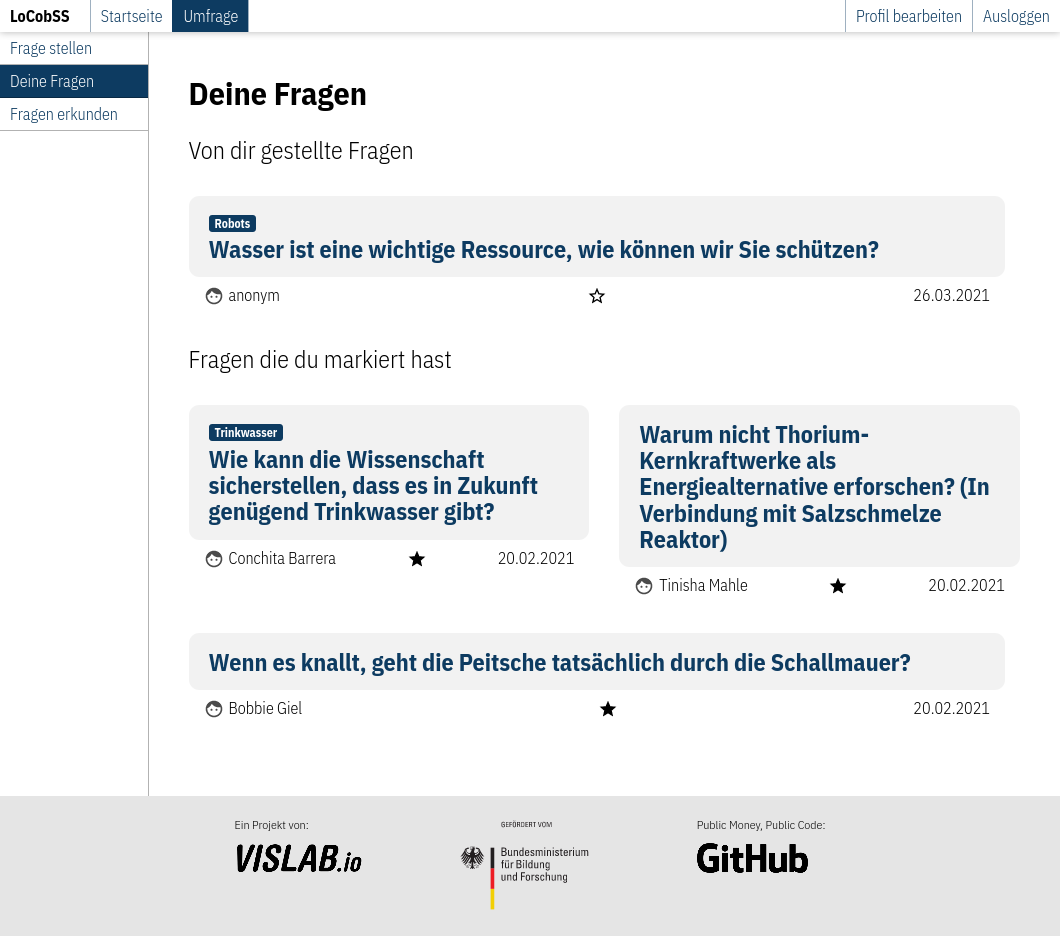
In der persönlichen Liste werden die eigenen Fragen und markierten Inhalte übersichtlich zusammengeführt.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/mylist.svelte
API: /user/questions
API: /user/question/like/:id
Die Administrationsansicht ist etwas funktionaler gestaltet. Von hier aus können Fragen schnell gelöscht, bearbeitet und kategorisiert werden.
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/questions/list.svelte
API: /questions
API: /question/delete/:id
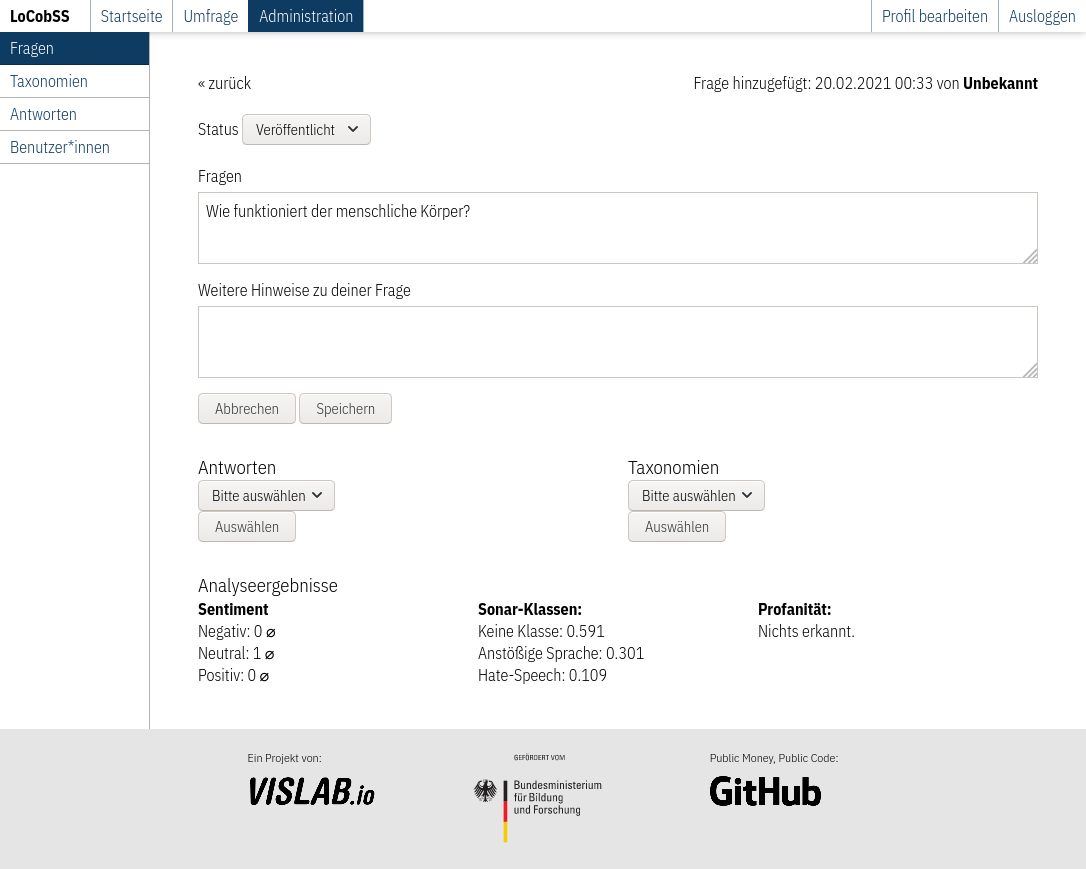
Über die Bearbeitungsansicht kann der Status der Fragen verändert werden (nur auf “veröffentlicht” gestellte Fragen, tauchen im öffentlichen Bereich auf), Zuordnungen zu Kategorien oder Antworten gemacht werden, sowie Textänderungen an den Fragen vorgenommen werden. Als zusätzliche Informationen werden die Ergebnisse der Sentiment- und Profanitäts-Analyse angezeigt.
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/questions/edit.svelte
API: /question/update/:id
In der Clusteransicht können Fragen inhaltlich in gemeinsame Taxonomien überführt werden. Siehe hierzu auch Kapitel 3.3.3
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/questions/cluster.svelte
API: /related/questions/cluster | /public/taxonomies | /taxonomy/assign | /taxonomy/create

Die über das Clustering erstellen Kategorien können später über die entsprechende Seite auch nachträglich bearbeitet werden.
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/taxonomy/list.svelte
API: /public/taxonomies
API: /taxonomy/delete/:id
5.2 Daten-gestütztes Storytelling
Die datengestützten Storytelling-Anwendungen sind ebenfalls in SVELTE entwickelt worden. Zu den Konzepten zur Personalisierung siehe Kapitel 4.1ff und zu den Inhalten der beiden Anwendungen siehe Kapitel 4.4 und 4.5. Im Folgenden geben wir einen kurzen Einblick in die datenwissenschaftlichen Arbeiten hinter den Anwendungen.
5.2.1 Klimawandel und Mobilität
Das Herz der Mobilitätsanwendung ist eine spezielle Routing-Engine zur Berechnung von CO2-Produktion auf bestimmten Strecken. Hierzu haben wir die Valhalla Routing Engine so modifiziert, dass statt dem Parameter Zeit nun CO2-Ausstoß zur Berechnung genutzt wird. Diese spezielle Version haben wir ebenfalls öffentlich zugänglich gemacht. Hierzu mussten wir erst CO2-Modelle generieren. Anschließend haben wir für die verschiedenen Mobilitätsprofile und Postleitzahlen statische Datenexports generiert, um eine möglichst performante Anwendung zu erzielen.
Der Code zur Anwendung ist auf GitHub zu finden.
5.2.1 Klimawandelrisiken in Deutschland
Die Personalisierung der Klimawandelrisiken ist nicht so komplex wie bei der Mobilitätsanwendung, dafür werden allerdings mehr Daten einbezogen. Daten zu Klimazonen, Verdichtungsgebieten und Überschwemmungen wurden für alle Postleitzahlen vorberechnet und als statische Datenexports bereitgestellt. Dasselbe wurde auch für die Klima- und Wetterdaten des Deutschen Wetterdienstes (DWD) gemacht, um die Graphen im letzten Abschnitt der Anwendung zu generieren.
Der Code zur Anwendung ist auf GitHub zu finden.