LoCobSS-documentation
Datenschutzkonforme Erhebung von Nutzer*innendaten
Datensparsamkeit & Datenvermeidung
Grundsätzlich sollten bei jeder Form von Datenerhebungen nur diejenigen Daten gesammelt werden, die zwingend notwendig sind. Während dies auf den ersten Blick nachvollziehbar und offensichtlich erscheint, verfolgen dennoch viele Services, Erhebungen, oder Anwendungen die Strategie, so viele Daten wie möglich zu erheben. Dies soll z.B. die Option offen halten, nachträglich Analysen durchzuführen, die zum Zeitpunkt der Datenerhebung noch nicht vorgesehen waren oder antizipiert werden (konnten). Die Identifikation und Festlegung der essenziellen Daten vor der Durchführung einer Datenerhebung verlangt demgegenüber eine ausführliche und gründliche Reflexion über die später vorgesehene Nachnutzung der Daten und einer klaren Artikulation der mit der Datenerhebung verfolgten Zwecke. Verfolgt man einen solchen datensparsamen Ansatz, kann man die Nutzer*innen sehr transparent darüber informieren, wozu ihre Daten genutzt werden. Gleichzeitig kann der individuelle Fußabdruck der Datensammlung signifikant verringert werden.
Trennen von Datenbeständen
Gleichzeitig sollte reflektiert werden, ob es zwingend notwendig ist, statistische Daten wie z.B. demographische Daten mit den Nutzer*innendaten (z.B. Username, Email, Passwort) abzuspeichern. Im Falle eines potentiellen Datendiebstahls könnten so Nutzer*innendaten, wie z.B. Email-Adressen, spezifischen demographischen Attributen zugeordnet. Ein Beispiel im Kontext der Befragung der Bürger*innen, bei dem es Sinn macht, diese beiden Ebenen zu trennen:
Ziel: Man möchte im Laufe des Prozesses und nach Abschluss des Projektes sicherstellen, dass eine möglichst gute Stichprobe der Bevölkerung an der Umfrage teilgenommen haben.
Dimensionen: Geschlecht, Alter und räumliche Verortung
Abfragemethoden:
- Geschlecht: Aus Inklusionsgründen sollte hier ein breites Spektrum an Möglichkeiten angeboten werden. Eine entsprechende nicht-binäre Auswahl von Geschlecht führt folglich auch dazu, dass einzelne Auswahlmöglichkeiten nur von einer im Vergleich kleineren Anzahl von Personen ausgewählt wird. Dies birgt wiederum die Gefahr, dass Informationen über eine kleine Untergruppe der Bevölkerung erhoben werden und bei einem Datendiebstahl weiteren Daten zugeordnet werden können. Hier muss abgewogen werden, wie granular die Datenerhebung und wie gut der Schutz der Privatsphäre sein soll.
- Alter: Für das gestellte Ziel sollte es ausreichen grobe Altersklassen zu bilden, um auch hier sehr kleine Untergruppen identifizierbar zu machen.
- Räumliche Verordnung: Umso gröber die räumliche Auflösung, umso höher der Schutz der Privatsphäre. In vielen Fällen wird es wahrscheinlich ausreichen, Bundesländer oder z.B. Postleitzahlenbereiche zu erheben, unter denen eine größere Gruppe an Personen gefasst sind.
Speicherung: Sind wir nur daran interessiert, mit diesen Daten Aussagen über die Qualität der Stichprobe treffen zu können, könnte man diese demographischen Daten komplett von den daran anknüpfenden Fragen und den Nutzer*innendaten trennen. So könnte man später die demographischen Attribute weder den eingereichten Fragen noch einzelnen Personen zuordnen. Die Aussagekraft über die Qualität der Stichprobe wäre davon nicht gemindert.
2.2.1 Implementierung
In den Prototypen haben wir die Trennung von demographischen Daten und Nutzer*innendaten exemplarisch implementiert. Siehe hierzu die technische Dokumentation in Kapitel 5.
Privatsphärenschutz und das Erheben von Attributen
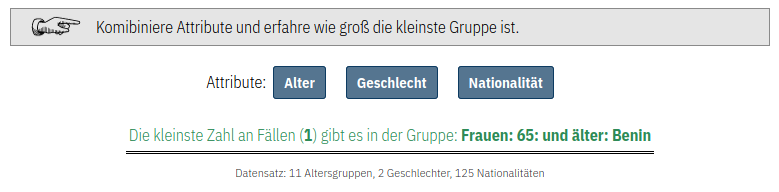
Das vorsichtige Abwägen beim Erheben von personenbezogenen Attributen ist notwendig, da über diese Attribute Personen in der realen Welt identifiziert werden können. Dies kann zum einen passieren, weil es innerhalb der untersuchten Zielgruppe sehr kleine Untergruppen mit bestimmten Attributen gibt. Wenn in der Datenbank nun eine Datensatz vorliegt, welcher genau diese seltenen Attribute hat, können wir diesen Datensatz einer Person zuordnen (oder wissen zumindest das eine von N Personen diesen Datensatz erstellt hat). Neben einer direkten Zuordnung darf nicht vergessen werden, dass diverse Unternehmen bereits enorme Mengen persönlicher Daten gesammelt haben. Kombiniert man diese mit den neu erhobenen Daten, können möglicherweise auch Rückschlüsse auf Individuen generiert werden.
Um diese Gefahren ganz praktisch anhand einiger Beispiele zu demonstrieren, haben wir eine interaktive Demo entwickelt.
Möglichkeiten zur Erhebung sensibler Information
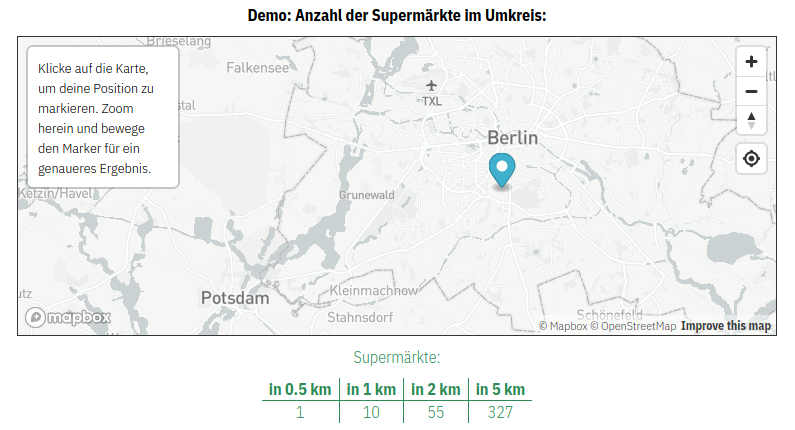
In manchen Fällen möchte man möglicherweise Daten erheben, die sehr persönlich sind und deren Missbrauch die Privatsphäre von Individuen verletzen könnte. Nehmen wir als Beispiel den exakten Wohnort der Person. Sollten wir tatsächlich konkrete Kontaktinformationen benötigen, z.B. zum postalischen Kontakt, müssen die Daten selbstverständlich erhoben werden (aber auch hier sollte erruiert werden, ob z.B. ein Trennen von Daten Sinn macht). In einigen Fällen wird der Wohnort aber nur erhoben, weil man davon ausgehend andere Attribute ableiten möchte: z.B. wohnt jemand in einer Großstadt oder eher auf dem Land. In all solchen Fällen, in denen hochaufgelöste Attribute erhoben werden, um anschließend niedrieg aufgelöste Attribute abzuleiten, empfiehlt es sich, dieses Ableiten direkt im Browser, auf Seiten der Nutzer*innen (client-side) durchzuführen. Ist man z.B. daran interessiert, ob jemand in einer Großstadt oder auf dem Land wohnt, kann man eine einfache Postleitzahlabfrage integrieren und anstatt der Postleitzahl selber, das Attribut Stadt/Land zurückgeben. Solche client-side classifications sind zwar für die Entwickler*innen komplexer zu implementieren, können aber so implementiert werden, dass diese für die Nutzer*innen keinen Unterschied in der Performance oder Interaktion darstellen.
Um diese Methode der client-side classification zu demonstrieren, haben wir eine interaktive Demo entwickelt.
Implementierung
Im Prototypen haben wir die Trennung von demographischen Daten und Nutzerdaten exemplarisch implementiert. Zusätzlich haben wir die oben beschriebene client-side classification implementiert. Beispielhaft wird hierzu die eingegebene Postleitzahl genutzt, um direkt im Browser die RegioStar Gem5 Klasse zu identifizieren (Metropole; Regiopole, Großstadt; Zentrale Stadt, Mittelstadt; Städtischer Raum; Kleinstädtischer / dörflicher Raum). Siehe hierzu die technische Dokumentation in Kapitel 5.
Weiterhin haben wir bei der Implementierung versucht, sogenannte “Dark Design Patterns” zu vermeiden und “Ethical Design” Prinzipien zu folgen:
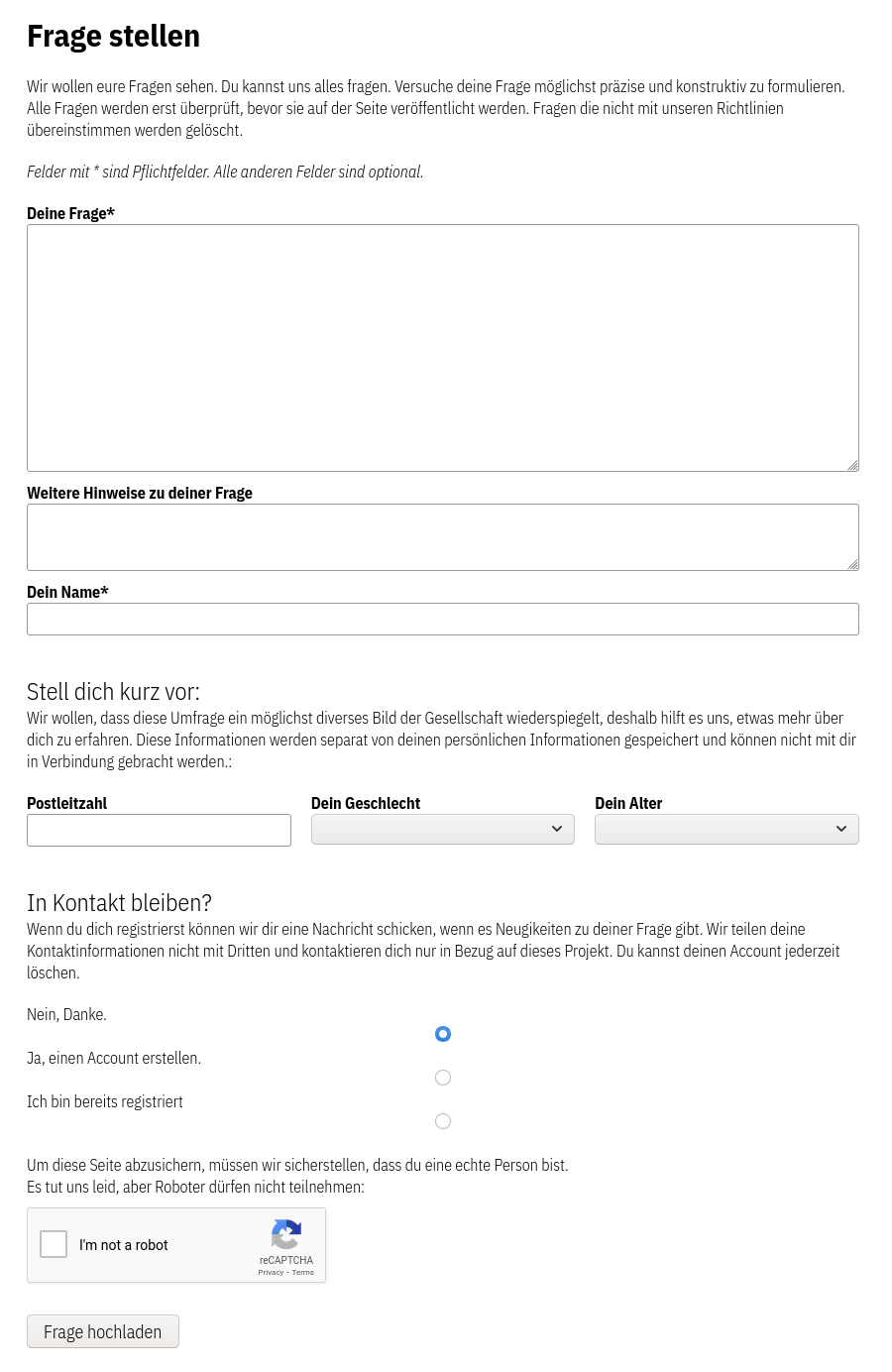
- Nur die Felder zu Pflichtfeldern machen, die wirklich notwendig sind. Pflichtfelder können Personen auch davon abschrecken, den Ausfüllprozess abzuschließen.
- Möglichst barrierearme Anforderungen an die Eingaben stellen (z.B. mindest- oder maximale Zeichenzahlen, Passwortvorgaben, etc.)
- Transparent erklären, wozu welche Daten erhoben werden und was damit geschieht. Zum Beispiel transparent erklären, warum demographische Daten erhoben werden und wie diese verarbeitet werden.
- Opt-in und nicht Opt-out. Die Vorteile einer möglichen Registrierung sollten deutlich gemacht werden und die Wahl der Nutzer*in überlassen werden.
- Sicherheitsmaßnahmen und Privatsphäre müssen häufig abgewägt werden. Wenn wir Bürger*innen erlauben wollen, Fragen zu stellen, ohne z.B. vorher ihre Email-Adresse zu validieren, müssen wir andere Maßnahmen integrieren, um illegale Aktivitäten auf der Seite zu verhindern. Wir haben als Beispielhafte Lösung reCaptcha implementiert. Wir haben explizit Version 2 genutzt, da die Privatsphäre bei dieser Variante besser geschützt wird.