Dr. Sebastian Meier | VISLAB.io
April 2021
Projektteam:
Sebastian Meier @ VISLAB.io, Projektleitung und Entwicklung
Fabian Dinklage, Visualisierung und Entwicklung
Katrin Glinka, Inhalte und Evaluation
Das Forschungsvorhaben LoCobSS wurde im Rahmen “Ideenwettbewerb(s) für innovative analoge und digitale Partizipationsformate und -technologien“ gefördert (Förderkennzeichen: 16IP103).
Im Wissenschaftsjahr 2022 soll ein großangelegtes Partizipationsverfahren durch das BMBF durchgeführt werden, um die Perspektive der Bürger*innen auf Wissenschaft und Forschung in Deutschland zu erfassen. Ein ähnliches Projekt gab es bereits 2018 in Belgien. Der Ideenwettbewerb soll innovative Konzepte für die Umsetzung des Prozesses in Deutschland generieren. Dabei sollen sich die Ideen auf drei Phasen fokussieren:
Das Vorhaben LoCobSS konzentriert sich auf digitale Aspekte des Prozesses und legt einen Fokus auf privatsphären-konforme Customization der User-Exprience, sowohl für die Bürger*innen als auch die Redakteur*innen des Ministeriums. Um die entwickelten Methoden und Konzepte anschaulich zu demonstrieren, wurden eine Reihe an Prototypen entwickelt, welche in den folgenden Kapiteln vorgestellt werden.
Im Rahmen von LoCobSS wurden eine Reihe von Methoden entwickelt und in Bezug auf ihren Mehrwert für das Partizipationsverfahren evaluiert. Die dabei entstandenen Softwarekomponenten können als prototypische Grundlagen für eine anschließende finale Implementation dienen (siehe technische Dokumentation in Kapitel 5). Die aus dem Vorhaben LoCobSS gewonnenen Erkenntnisse sollen zukünftige Ausschreibungen und weitere Entwicklungen zum Partizipationsverfahren leiten und unterstützen:
Nicht zuletzt die Entwicklung der Corona-Warn-App haben gezeigt, dass der Anspruch an und das Bewusstsein für das Thema Privatsphäre in der Bevölkerung weiter zunimmt. Für öffentliche Institutionen und Ministerien sollte diesem Thema folglich höchste Priorität zuteil werden.
Der Schutz der Privatsphäre steht einer Erhebung statistischer Daten nicht im Wege. Es sollten dabei einige Grundsätze beachtet werden:
Weitere Hilfestellungen finden Sie in Kapitel 2.
Um eine möglichst breite Gruppe der Bevölkerung am Verfahren zu beteiligen, sollten Barrieren niedrig gehalten werden:
Weitere Hilfestellung hierzu ist im Prototypen zur Erfassung von Fragen in Kapitel 2 aufgeführt.
Kommentar: Das Vorhaben LoCobSS hat sich auf digitale Komponenten des Partizipationsverfahren konzentriert. Für eine tatsächlich inklusive Gestaltung des Verfahrens sollten diese digitalen Komponenten nur einen Teil einer breit aufgestellten Aktivierungsstrategie darstellen und mit analogen Komponenten und einer breit aufgestellten Outreach-Kampagne kombiniert werden.
Während der Fokus des Partizipationsverfahrens klar auf der Aktivierung und Beteiligung von Bürger*innen liegt, sollte nicht vergessen werden, dass ein gut ausgestattetes Team für die Redaktion der Inhalte unabdingbar ist. Das vergleichbare Projekt und Partizipationsverfahren in Belgien hat über 10.000 Fragen generiert. Entsprechend ist (bei vergleichbarer Durchführung) damit zu rechnen, dass in Deutschland über 50.000 Fragen zu erwarten sind. Die von Bürger*innen eingereichten Fragen müssen validiert (Relevanz-Check, Schimpfwörter entfernen, missbräuchliche Einreichungen löschen oder nicht freigeben, etc.) und schließlich kategorisiert werden. LoCobSS hat die Möglichkeiten der Automatisierung bzw. automatisierten Unterstützung dieser Schritte auf Basis der Daten des belgischen Verfahrens evaluiert und zieht daraus folgende Schlüsse:
Insgesamt lässt sich zu algorithmischen Verfahren für die Textanalyse zusammenfassend festhalten, dass diese häufig auf die englische Sprache hin optimiert sind. Durch eine vorgeschaltete Übersetzung der Inhalte kann diese Einschränkung jedoch in vielen Bereich umgangen werden. Bei sprachspezifischen Problemen, wie z.B. Beleidigungen, stoßen gängige Verfahren zur automatisierten Textanalyse ohne weitere Anpassungen (z.B. Optimierung durch erweiterte Trainingsdaten bei Machine Learning Prozessen) aber an ihre Grenzen.
Details zum Prototypen für die Kategorisierung von Beiträgen in Kapitel 3.
Durch Customization-Methoden kann die User-Experience personalisiert werden und so zu einer intensiveren Auseinandersetzung mit der Plattform führen. Um das explorieren der Inhalte auf der Plattform zu erleichtern und Serendipität zu fördern, sollten neben einer klassischen Suche auch Recommender-Funktionalitäten integriert werden. Hierbei unterscheidet man zwischen Content-based Recommendation und Collaborative Recommendation. Für letzteren Ansatz müssten allerdings die Interaktionen der Nutzer*innen erfasst werden. Zum Schutz der Privatsphäre der Nutzer*innen sollte dieser Ansatz nur mit bedacht durchgeführt werden. Im Rahmen dieses Vorhabens haben wir daher einen prototypischen Content-based Recommender entwickelt, der keinerlei Nutzer*innendaten speichert und auf denselben Prinzipien des Redaktionswerkzeugs für die Kategorisierung aufbaut.
Mehr zum Content-based Recommender in Kapitel 3.
Klassische Wissenschaftsvermittlung ist häufig statisch, unidirektional und textlastig. Im Rahmen von LoCobSS haben wir in Abgrenzung dazu mit modernen Methoden des Datenjournalism und das data-driven Storytellings neue Formate zur Vermittlung wissenschaftlicher Erkenntnisse in Form von zwei interaktiven Prototypen entwickelt, die sich individuell personalisieren lassen. So wird die Lebenswelt der Nutzer*innen in die Kommunikation mit einbezogen und erlaubt ihnen, direkte Bezüge zwischen ihrer Lebenswelt und den vermittelten Inhalten herzustellen. Durch interaktive Elemente wird die Aufmerksamkeit der Nutzer*innen gebunden. Explorative Elemente laden zu einer tiefergehenden Auseinandersetzung mit der Materie ein. Auch bei den Ansätzen zur Personalisierung bleibt die Privatsphäre der Nutzer*innen gewahrt.
Eine detaillierte Erklärung der beiden Prototypen folgt in Kapitel 4.
Kommentar: Falls auf diesen Prototypen aufbauende ähnliche Formate zur Vermittlung wissenschaftlicher Erkenntnisse und Themen häufiger implementiert und angepasst werden sollen, würde es Sinn machen, diese Konzepte zu standardisieren und entsprechende Frameworks zur Verfügung zu stellen. Dies würde es ermöglichen, neue Themen einfach und nachhaltig durch Nutzung des Frameworks zu erschließen und zu kommunizieren.
Wie lassen sich die Fragen der Bürger*innen von den Wissenschaftler*innen praxisnah und forschungsrelevant auswerten?
Es ist mit einer extrem großen Zahl an Inhalten zu rechnen, die von den Redakteur*innen bearbeitet werden müssen. Mit dem Ziel, Teile der Verwaltung dieser Inhalte technisch unterstützen oder automatisieren zu können, wurden verschiedene verfahren des Maschinellen Lernens (ML) exploriert. Die erfolgreichsten Ergebnisse wurden im Bereich der Kategorisierung (Taxonomien) erzielt. Hierzu wurde ein kooperatives ML-System entwickelt, welches die Redakteur*innen bei ihrer Arbeit unterstütz und gleichzeitig den Bürger*innen erlaubt die Inhalte einfach zu durchsuchen. Siehe hierzu Kapitel 3.
Wie lässt sich eine solche Erhebung mit dem Schutz der Privatsphäre der teilnehmenden Personen vereinen?
Diese Dokumentation enthält Empfehlungen (siehe Kapitel 2) zur Konzeption und Umsetzung von Umfragen mit Fokus auf Wahrung der Privatsphäre der Teilnehmer*innen. Für die Erhebung von daraus abgeleiteten Attributen wurde ein client-side classification Ansatz entwickelt. Die Empfehlungen und client-side classification wurden beispielhaft in einem Survey Prototypen (siehe Kapitel 5) implementiert.
Wie kann die Relevanz wissenschaftlicher Inhalte für die Bürger*innen erhöht werden?
Welche Potentiale ergeben sich durch die Erhebung des räumlichen Kontextes in Hinblick auf die individuelle Relevanz der Inhalte?
In Fortführung der Personalisierungsmethoden wurden zwei exemplarische Wissenschaftskommunikations-Anwendungen entwickelt, welche den räumlichen Kontext der Leser*innen nutzen, um das interaktive Storytelling zu personalisieren. Mehr in Kapitel 4.
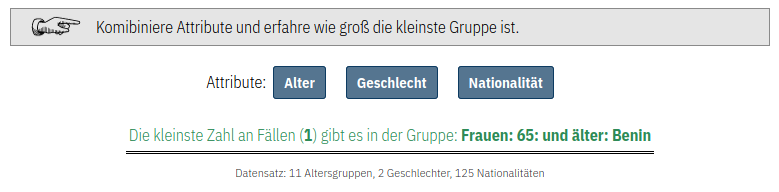
Grundsätzlich sollten bei jeder Form von Datenerhebungen nur diejenigen Daten gesammelt werden, die zwingend notwendig sind. Während dies auf den ersten Blick nachvollziehbar und offensichtlich erscheint, verfolgen dennoch viele Services, Erhebungen, oder Anwendungen die Strategie, so viele Daten wie möglich zu erheben. Dies soll z.B. die Option offen halten, nachträglich Analysen durchzuführen, die zum Zeitpunkt der Datenerhebung noch nicht vorgesehen waren oder antizipiert werden (konnten). Die Identifikation und Festlegung der essenziellen Daten vor der Durchführung einer Datenerhebung verlangt demgegenüber eine ausführliche und gründliche Reflexion über die später vorgesehene Nachnutzung der Daten und einer klaren Artikulation der mit der Datenerhebung verfolgten Zwecke. Verfolgt man einen solchen datensparsamen Ansatz, kann man die Nutzer*innen sehr transparent darüber informieren, wozu ihre Daten genutzt werden. Gleichzeitig kann der individuelle Fußabdruck der Datensammlung signifikant verringert werden.
Gleichzeitig sollte reflektiert werden, ob es zwingend notwendig ist, statistische Daten wie z.B. demographische Daten mit den Nutzer*innendaten (z.B. Username, Email, Passwort) abzuspeichern. Im Falle eines potentiellen Datendiebstahls könnten so Nutzer*innendaten, wie z.B. Email-Adressen, spezifischen demographischen Attributen zugeordnet. Ein Beispiel im Kontext der Befragung der Bürger*innen, bei dem es Sinn macht, diese beiden Ebenen zu trennen:
Ziel: Man möchte im Laufe des Prozesses und nach Abschluss des Projektes sicherstellen, dass eine möglichst gute Stichprobe der Bevölkerung an der Umfrage teilgenommen haben.
Dimensionen: Geschlecht, Alter und räumliche Verortung
Abfragemethoden:
Speicherung: Sind wir nur daran interessiert, mit diesen Daten Aussagen über die Qualität der Stichprobe treffen zu können, könnte man diese demographischen Daten komplett von den daran anknüpfenden Fragen und den Nutzer*innendaten trennen. So könnte man später die demographischen Attribute weder den eingereichten Fragen noch einzelnen Personen zuordnen. Die Aussagekraft über die Qualität der Stichprobe wäre davon nicht gemindert.
In den Prototypen haben wir die Trennung von demographischen Daten und Nutzer*innendaten exemplarisch implementiert. Siehe hierzu die technische Dokumentation in Kapitel 5.
Das vorsichtige Abwägen beim Erheben von personenbezogenen Attributen ist notwendig, da über diese Attribute Personen in der realen Welt identifiziert werden können. Dies kann zum einen passieren, weil es innerhalb der untersuchten Zielgruppe sehr kleine Untergruppen mit bestimmten Attributen gibt. Wenn in der Datenbank nun eine Datensatz vorliegt, welcher genau diese seltenen Attribute hat, können wir diesen Datensatz einer Person zuordnen (oder wissen zumindest das eine von N Personen diesen Datensatz erstellt hat). Neben einer direkten Zuordnung darf nicht vergessen werden, dass diverse Unternehmen bereits enorme Mengen persönlicher Daten gesammelt haben. Kombiniert man diese mit den neu erhobenen Daten, können möglicherweise auch Rückschlüsse auf Individuen generiert werden.
Um diese Gefahren ganz praktisch anhand einiger Beispiele zu demonstrieren, haben wir eine interaktive Demo entwickelt.
In manchen Fällen möchte man möglicherweise Daten erheben, die sehr persönlich sind und deren Missbrauch die Privatsphäre von Individuen verletzen könnte. Nehmen wir als Beispiel den exakten Wohnort der Person. Sollten wir tatsächlich konkrete Kontaktinformationen benötigen, z.B. zum postalischen Kontakt, müssen die Daten selbstverständlich erhoben werden (aber auch hier sollte erruiert werden, ob z.B. ein Trennen von Daten Sinn macht). In einigen Fällen wird der Wohnort aber nur erhoben, weil man davon ausgehend andere Attribute ableiten möchte: z.B. wohnt jemand in einer Großstadt oder eher auf dem Land. In all solchen Fällen, in denen hochaufgelöste Attribute erhoben werden, um anschließend niedrieg aufgelöste Attribute abzuleiten, empfiehlt es sich, dieses Ableiten direkt im Browser, auf Seiten der Nutzer*innen (client-side) durchzuführen. Ist man z.B. daran interessiert, ob jemand in einer Großstadt oder auf dem Land wohnt, kann man eine einfache Postleitzahlabfrage integrieren und anstatt der Postleitzahl selber, das Attribut Stadt/Land zurückgeben. Solche client-side classifications sind zwar für die Entwickler*innen komplexer zu implementieren, können aber so implementiert werden, dass diese für die Nutzer*innen keinen Unterschied in der Performance oder Interaktion darstellen.
Um diese Methode der client-side classification zu demonstrieren, haben wir eine interaktive Demo entwickelt.
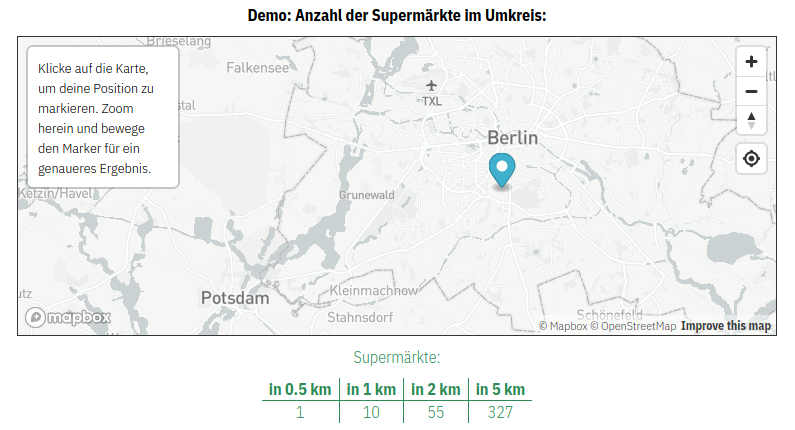
Im Prototypen haben wir die Trennung von demographischen Daten und Nutzerdaten exemplarisch implementiert. Zusätzlich haben wir die oben beschriebene client-side classification implementiert. Beispielhaft wird hierzu die eingegebene Postleitzahl genutzt, um direkt im Browser die RegioStar Gem5 Klasse zu identifizieren (Metropole; Regiopole, Großstadt; Zentrale Stadt, Mittelstadt; Städtischer Raum; Kleinstädtischer / dörflicher Raum). Siehe hierzu die technische Dokumentation in Kapitel 5.
Weiterhin haben wir bei der Implementierung versucht, sogenannte “Dark Design Patterns” zu vermeiden und “Ethical Design” Prinzipien zu folgen:
Ein Großteil der Bemühungen rund um die Befragung von Bürger*innen stellt die Erhebung und Partizipation in den Mittelpunkt. Gleichzeitig sollte allerdings nicht vergessen werden, dass auch die Mitarbeiter*innen bei der Handhabung und Verarbeitung der eintreffenden Fragen unterstützt werden müssen. Wenn das Verfahren in Belgien7 als Grundlage genommen wird, sollten in Deutschland bei vergleichbarer Umsetzung um die 50.000 Inhalte durch die Bürger*innen generiert werden. Diese Inhalte müssen überprüft, freigegeben und kategorisiert werden. Wenn jeder Frage nur eine Minute Aufmerksamkeit geschenkt wird, bedeutet dies über 100 Arbeitstage nur mit der reinen Administration der Inhalte.
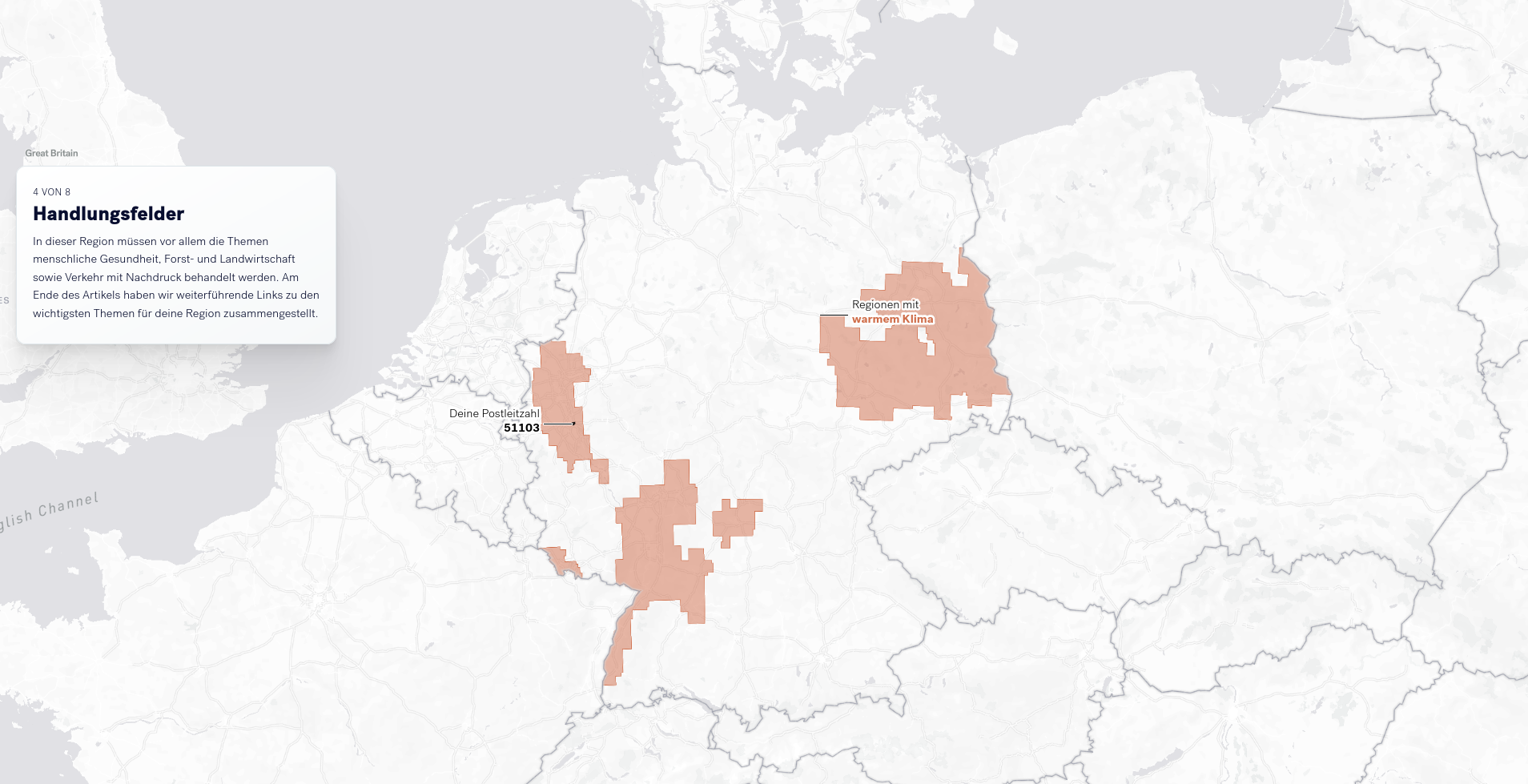
Gut kategorisierte und kuratierte Inhalte stellen auch gleichzeitig einen Mehrwert für die Nutzer*innen der Plattform dar. Deshalb sehen wir einen doppelten Nutzen darin, die Redakteur*innen bei ihrer Arbeit zu unterstützen. Bezüglich dieser Aufgaben haben uns die Organisator*innen anderer Beteiligungsverfahren und öffentlicher Plattformen zwei primäre Aufgaben genannt, bei denen Unterstützung besonders hilfreich wäre: Identifizieren von unangebrachten Inhalten und das Kategorisieren von Inhalten.
Im Rahmen des Vorhabens LoCobSS haben wir uns insbesondere mit Methoden der automatisierten Verarbeitung von Inhalten beschäftigt. Im Folgenden präsentieren wir die von uns prototypisch implementierten Dienste und deren Evaluation. Die technische Dokumentation befindet sich in Kapitel 5.
Um die folgenden Ansätze evaluieren zu können, wurden vergleichbare Testdaten benötigt. Zu diesem Zweck wurde ein Harvester entwickelt, welcher die Daten des belgischen Beteiligungsverfahrens7 aggregiert und strukturiert für dieses Vorhaben aufbereitete.
Für weitere Details siehe das Repository des Harvesters.
Bevor Eingaben der Bürger*innen über die Plattform veröffentlicht werden, sollten diese dahingehend überprüft werden, ob sie den inhaltlichen Guidelines entsprechen. Beispiele für Inhalte die in diesem Schritt identifiziert und gefiltert werden sollten, sind z.B. rassistische, sexistische, obszöne oder gewaltverherlichende Inhalte. Eine große Herausforderung bei der Nutzung automatisierter Verfahren ist, dass die meisten algorithmischen Verfahren auf englischsprachigen Inhalten und Daten trainiert und optimiert sind. Insbesondere bei Thematiken wie Schimpfwörtern sind aber sprachliche Nuancen und z.B. auch spezielle Schreibweisen sehr wichtig. Hinzu kommen zweideutige Sätze, bei denen Algorithmen nur schwer die tatsächlich intendierte Bedeutung fehlerfrei zuordnen können. Entsprechend zeigte sich in den Tests auch, dass eine Menge unangebrachte Inhalte von den algorithmischen Analysemethoden nicht erkannt wurden. Deshalb kann die Identifikation von Hate Speech im aktuellen Implementationszustand nur als Hinweis an die Redakteur:innen dienen, nicht aber als automatisierter Filter eingesetzt werden.
Um Ansätze für englische Sprache nutzen zu können, haben wir die Eingaben der Nutzer*innen automatisiert ins englische übersetzt.
Sollte man solch einen Ansatz weiterverfolgen, müsste man gute deutsche Trainingsdaten und deutsche Vokabularien generieren. Während dies ein grundsätzlich löbliches Vorhaben wäre, welches sicherlich auch anderen Entwickler*innen und Forscher*innen zu Gute käme, ist es fraglich, ob dies im Rahmen eines solchen Vorhabens finanziell angemessen und umsetzbar wäre wäre.
Die meisten großen Content-Plattformen nutzen sogenannte Micro-Job oder Micro-Task Plattformen, bei denen Personen für Kleinstaufgaben bezahlt werden. Größere Unternehmen wie z.B. Facebook haben eigene Content-Moderators, um Hate-Speech oder andere unangebrachte Inhalte zu filtern und zu löschen. Beide Methoden sind nur bedingt zu empfehlen, da Micro-Jobber*innen häufig weit unter dem Mindestlohn bezahlt werden und psychisch stark beanspruchende Arbeit leisten müssen. Diese Problematik sollte bei ähnlichen Ansätzen für die Content-Redaktion berücksichtigt werden. Empfehlenswerter wäre es, Projektstellen zu schaffen, wodurch angemessene Löhne und Arbeitsbedingungen sichergestellt werden können.
Um die eingehenden Beiträger der Bürger*innen analysieren zu können und nachnutzbar zu machen, müssen diese kategorisiert werden. Hierzu müssen aus den gesamten Inhalten übergreifende Thematiken abgeleitet werden und die Inhalte entsprechend mit Schlagworten (Tags) oder Kategorien (Taxonomien) versehen werden. Im Gegensatz zur Betrachtung und Bewertung individueller Inhalte, müssen bei diesem Aufgabe viele Inhalte gleichzeitig miteinander verglichen werden. Nach Experimenten mit verschiedenen Natural Language Processing (NLP) und Machine Learning (ML) Verfahren, haben wir uns hierbei für einen zweistufigen Prozess entschieden, der vielversprechende Ergebnisse liefert.
Ein in der algorithmischen Textanalyse weit verbreitetes Verfahren ist das Umwandeln von Texten in Vektoren. Das Verfahren basiert darauf, dass ein künstliches Neuronales Netzwerk auf einem großen Text-Korpus trainiert wird. Stark abstrahiert dargestellt lernt das Netzwerk dabei, Strukturen und Ähnlichkeiten von Textbausteinen zu erkennen. Später kann das künstliche Neuronale Netzwerk genutzt werden, um Textbausteinen einen mehrdimensionalen Vektor zuzuordnen. Über diese Vektoren können dann z.B. Vergleiche angestellt werden, um die Ähnlichkeit von Textbausteinen festzustellen. Hierbei gibt es Verfahren die für einzelne Wörter (z.B. word2vec) optimiert sind und andere, die ganze Texte analysieren können. Wir haben für diesen Schritt den von Google Forscher*innen entwickelten Universal Sentence Encoder in Version 4 genutzt.
Zur einfachen Analyse wurde ein Service entwickelt, welcher Texte in 512-dimensionale Vektoren umwandelt.
Der Vorteil dieses Verfahrens ist, dass die Berechnung der Ähnlichkeiten sowohl mit sehr wenigen Inhalten funktioniert, als auch mit sehr vielen. So kann, schon während die ersten Inhalte eintreffen, sehr früh eine erste Analyse durchgeführt werden.
Aufbauend auf den Text-Vektoren lässt sich eine Distanzmatrix erstellen, um schnell Ähnlichkeiten zwischen einzelnen Texten abzuleiten. So können z.B. Content-Recommendations basiernd auf den berechneten Text-Ähnlichkeiten durchgeführt werden. Hierzu haben wir einen einfachen Service entwickelt, welcher zu einem nutzer*innengenerierten Inhalt die ähnlichsten Inhalte zurückgibt.
Im Laufe der Entwicklung dieser Module haben wir unterschiedliche Methoden aus den Bereichen des Topic-Modellings und des Clusterings getestet. Topic-Modelling beschäftigt sich im NLP mit dem Identifizieren von übergreifenden Themen innerhalb eines Textes. Clustering Methoden wiederum versuchen ähnliche Datensätze zu identifizieren, in unserem Fall basierend auf den Werten der Vektoren.
Beide Ansätze haben keine zufriedenstellenden Ergebnisse geliefert. Deshalb haben wir das Prinzip des Clusterings genommen und daraus einen kollaborativen Ansatz entwickelt, bei welchem Nutzer*innen und Algorithmen gemeinsam versuchen, passende Gruppen zu bilden.
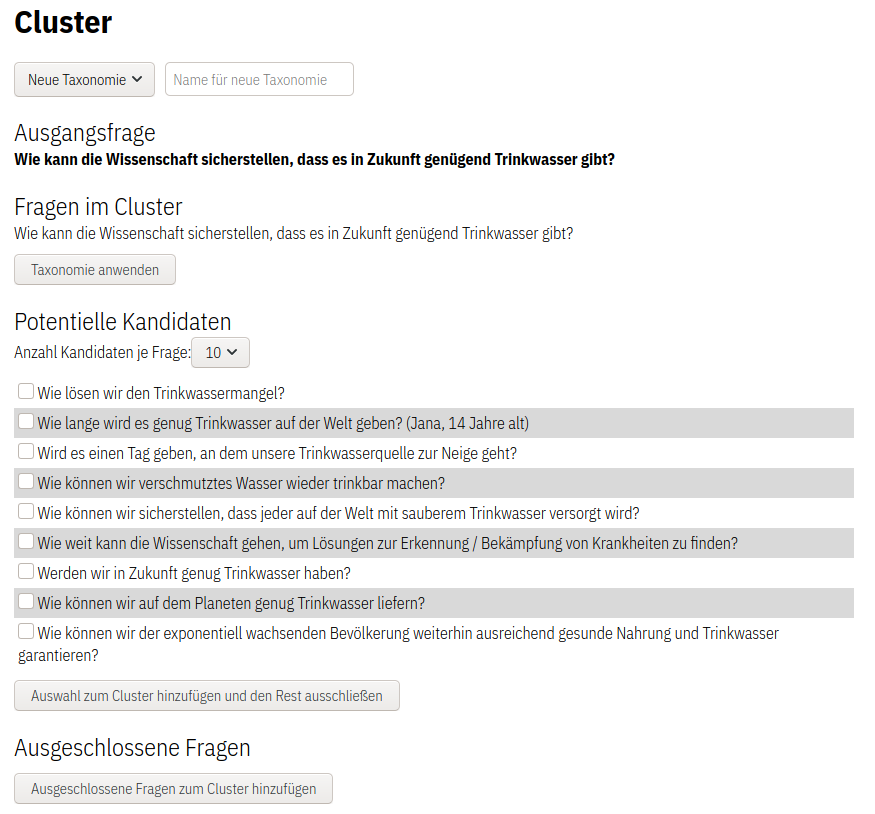
Die Redakteur*innen wählen dazu erst einen Inhalt als Ausgangspunkt aus (siehe Abbildung Ausgangsfrage). Das System sucht nun zu diesem Objekt ähnliche Inhalte heraus (siehe Abbildung Potentielle Kandidaten). Aus diesen “Ähnlichkeits-Kandidaten” können nun die tatsächlich ähnlichen Objekte ausgewählt werden. Diese werden dann dem aktuellen Cluster hinzugefügt. Alle nicht ausgewählten Kandiaten landen in der Liste ausgeschlossener Inhalte. Nachdem eine Auswahl getätigt wurde, nutzt das System die neuen Objekte, um daraus weitere ähnliche Inhalte abzuleiten. So können mit nur wenigen Clicks hunderte Objekte in Kategorien kombiniert werden. Abschließend kann man der Sammlung einen Namen geben und so die Navigation und Suche für Besucher*innen der Seite unterstützen.

Als visuelles Feature werden die Inhalte der Plattform in einer zweidimensionalen Punktewolke abgebildet. Mit Hilfe einer Dimensionsreduktion (t-SNE) werden die Vektoren auf zwei Dimensionen reduziert. In dieser Wolke wird auch die aktuelle Auswahl des Cluster angezeigt. In der aktuellen Variante ist dies nur eine statische Visualisierung der ausgewählten Inhalte, zukünftig könnte man dies dahingehend erweitern, dass die Auswahl auch über die Visualisierung durchgeführt werden kann.
Neben der Kategorisierung durch die Redakteur*innen haben wir ein weiteres Feature implementiert, was einen crowd-sourcing Ansatz bei der Kategorisierung verfolgt. Jede*r Bürger*in die*\der einen Inhalt auf der Plattform generiert, erhält nach dem Abschicken Vorschläge verwandter Inhalte. Die Bürger*innen können dann Feedback geben, ob diese Inhalte mit ihrer Frage verwandt sind oder nicht.
Hinweis: Während die nutzer*innenseitige Kategorisierung vollständig implementiert ist, fehlt noch eine Kombination mit dem System der Redakteur*innen. Die direkte Vektorisierung des Textes dauert im aktuellen Setup etwas länger. Aus Kostengründen geht der Klassifizierungsservice automatisch in einen Ruhezustand. Das “Erwachen” aus diesem Ruhezustand benötigt etwas Zeit. Bei einer finalen Integration könnte man dieses Delay auf ein Minimum reduzieren.
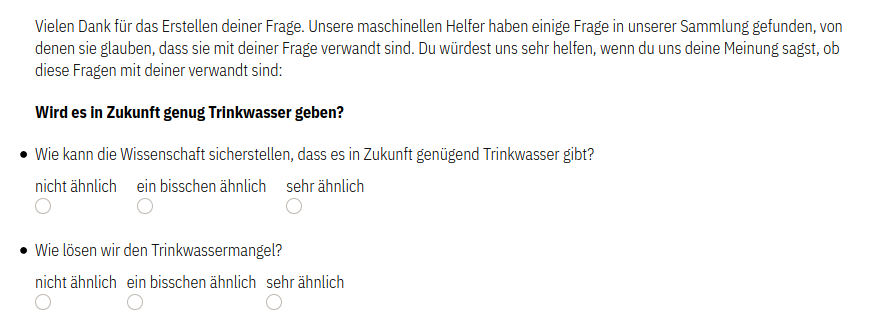
Ähnlich wie das Kategorisieren der Redakteur*innen, können die zugrundeliegenden Daten auch genutzt werden, um den Nutzer*innen der öffentlichen Seite Inhalte zu empfehlen. Diese Funktionalität ist bereits im aktuellen Prototypen integriert (siehe Abbildung unten). Wählt man eine Frage aus, werden ähnliche Inhalte angezeigt. Um Serendipität zu fördern, sind dies nicht nur die “ähnlichsten” Inhalte sondern auch Inhalte, die etwas weiter entfernt sind. Die Auswahl wird leicht randomisiert, sodass bei jedem Besuch andere ähnliche Inhalte angezeigt werden.
Auch wenn diese Funktion während unserer Recherchen nicht als eines der wichtigsten Features für eine Partizipationsplattform aufkam, haben wir die Funktion von automatisierten Sentiment Analysen im Rahmen der Entwicklung von Hate-Speech-Detection exploriert. Die Ergebnisse waren sehr durchmischt. Teils werden Einstellungen zu bestimmten Themen sehr gut erkannt, häufig werden Einstellungen aber als eher neutral vom System bewertet. Für zukünftige Entwicklungen haben wir auch hierzu einen Service entwickelt, welcher entsprechende Sentiment-Werte für einen eingegebenen Text zurückgibt.
Auf Benutzer*innen zugeschnittenes, datengestütztes Storytelling im Web
Klassische Wissenschaftskommunikation ist nach wie vor meist statisch, unidirektional und textlastig. Die strukturelle Nähe zu akademischen Publikationen macht diese nur schwer zugängig für viele interessierte Bürger*innen. Alternativen zu diesen Kommunikationspraktiken finden sich beispielsweise im Bereich des Daten-Journalismus oder der Daten- und Informationsvisualisierung. Dort werden Ansätze entwickelt und genutzt, welche den aktuellen Seh- und Nutzungsgewohnheiten der Leser*innen entsprechen. In diesem Teilabschnitt des LoCobSS Vorhabens wurden zwei exemplarische Anwendungen entwickelt, welche aufzeigen sollen, wie man mit diesen Methoden des datengestützten Storytellings auch wissenschaftliche Inhalte bürger*innennah vermitteln kann. Darüber hinaus wurden Methoden der Personalisierung entwickelt, um es den Leser*innen zu erleichtern, Bezüge zwischen den wissenschaftlichen Ergebnissen und der eigenen Lebenswelt herzustellen.
Die zunehmende Verfügbarkeit von Daten, barrierearmen Werkzeuge zur Erstellung von Visualisierungen und Bemühungen von Akteur*innen wie Datenjournalist*innen, haben in den letzten Jahren dazu beigetragen, dass Visualisierungen von Daten und Informationen nicht mehr nur in der Fachliteratur zu finden sind, sondern Einzug in die Massenmedien gehalten haben. Besonders hervorzuheben für ihre herausragende datenjournalistische Arbeit auf diesem Gebiet sind z.B. folgende Plattformen:
Deutschland
Europa
Weltweit
Wie in der beispielhaften Abbildung aus der New York Times oben zu sehen, gehen die Formen von Visualisierungen mittlerweile weit über einfache Balken- und Liniendiagramme hinaus und bieten komplexe Darstellungen und Analysemöglichkeiten. Diese komplexen Formen der Visualisierungen sollten aber mit Bedacht genutzt werden, da die Zunahme solcher Darstellungen nicht zwingend Hand-in-Hand geht mit der Visual-Literacy in der breiten Leserschaft. Deshalb haben wir in den folgenden Prototypen versucht, die visuelle und informationelle Komplexität möglichst gering zu halten.
Weiterführende Lektüre zum Thema Datenjournalismus:
Besonders wenn es um eher abstrakte wissenschaftliche Phänomene geht, ist es wichtig, den Leser*innen Bezüge zur eigenen Lebenswelt aufzuzeigen, um die Relevanz dieser Thematiken deutlich zu machen. Beim Beispiel der Klimawandelkommunikation, welche wir in unseren Prototypen thematisiert haben, wird dies besonders deutlich. Im Gegensatz zum lokalen Wetter beschreibt der Klimawandel langfristige und großräumliche Veränderungen. Hierdurch kann es für Bürger*innen schwierig sein, Bezüge zum eigenen Leben und Handeln herzustellen. Die Herausforderung liegt also darin, diese Verbindungen herzustellen. Je persönlicher die Bezüge, umso einfacher die fällt es, eine Verbindung zur Lebenswelt der Bürger*innen herzustellen.
Den folgenden Prototypen liegt folgendes Modell zu Grunde (siehe Meier & Glinka 2017): 1) es gibt einen Datenraum, welcher für die Visualisierung genutzt wird (z.B. Klimazonen in Deutschland), 2) es gibt Leser*innen, die bestimmte Eigenschaften haben (Datenattribute, wie z.B. der Wohnort). Auf diesem Modell aufbauend, kann man die abstrahierten Datenattribute einer Leser*in mit dem Datenraum abgleichen und verschiedene Operationen durchführen:
Bei mehrdimensionen Datenräumen kann eine Dimensionsreduktion genutzt werden, um möglichst ähnliche Datenobjekte im Vergleich zur Leser*in zu identifizieren, um so einen Einstieg in den größeren Datenraum zu erleichtern.
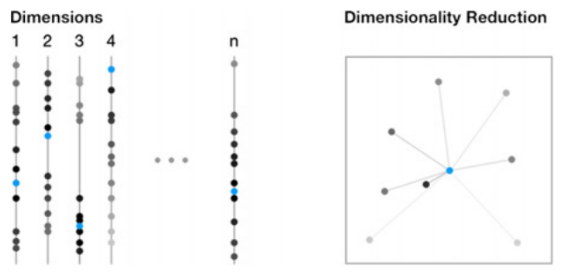
Vergleichbare Prinzipien zur Identifikation ähnlicher Datenpunkte oder Gruppen ähnlicher Datenpunkte lassen sich auch mit anderen Verfahren durchführen, wie z.B. KNN oder KMC.
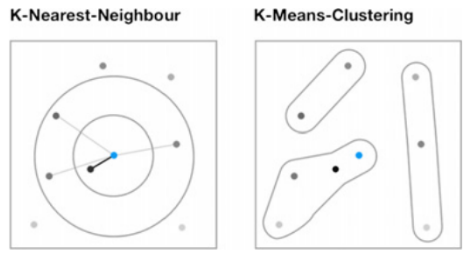
Die Attribute der Leser*in können ebenso als Filter genutzt werden, um den Datenraum herunterzubrechen und zu verkleinern.
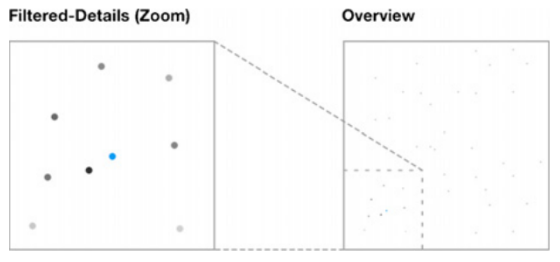
In den beiden Prototypen wurde dieses abstrakte Modell anschaulich umgesetzt:
Weiterführende Literatur zur Personalisierung von Visualisierungen:
Bei der Umsetzung wurde die in Kapitel 2 beschriebene client-side classifiction genutzt, in Kombination mit vorberechneten statischen Datenextrakten. Hierdurch konnte eine privatsphären-konforme Implementierung der folgenden Prototypen sichergestellt werden. Während der Interaktion mit den Visualisierungen werden keine Daten über die Nutzer*innen gespeichert.
Beide Prototypen nutzen das sogenannte Scrollytelling-Konzept. Die Benutzer*innen müssen zur Interaktion einfach nur scrollen. Dadurch werden Animationen und Interaktionen ausgelöst. Diese niedrigschwellige Form der Interaktion ist sehr intuitiv und funktioniert sowohl auf Desktop als auch auf mobilen Endgeräten. Die Nutzer*innen können durch das Scrolling die Gewschwindigkeit der Erzählung selber beeinflussen und steuern.
Für weitere technische Details der Umsetzung, siehe Kapitel 5.
Um den Klimawandel zu verlangsamen, muss der Ausstoß schädlicher Treibhausgase reduziert werden. CO2 ist unter den Treibhausgasen einer der wichtigsten Treiber des Klimawandels. 30% der CO2-Emissionen in Europa werden durch den Verkehr verursacht. PKWs sind für mehr als 13% der CO-Emissionen in Europa verantwortlich. Während wir als Bürger*innen nur indirekten Einfluss auf viele Formen der CO2-Produktion haben, können wir sehr direkten Einfluss auf unsere tägliche Mobilität nehmen und damit einen Beitrag leisten.
In diesem ersten Prototypen sollen verschiedene Szenarien geplanter CO2-Reduktion und deren Auswirkungen auf unsere Mobilität aufgezeigt werden.

Hierzu wird den Leser*innen zuerst aufgezeigt, welche Bedeutung dem PKW in Bezug auf CO2-Emissionen zukommt. Hierzu werden animierte Grafiken genutzt, welche mit kurzen Absätzen unterstützt werden. Die Informationen werden in kleine Einheiten aufgebrochen und in einer Kombination aus Text und Visualisierung vermittelt.
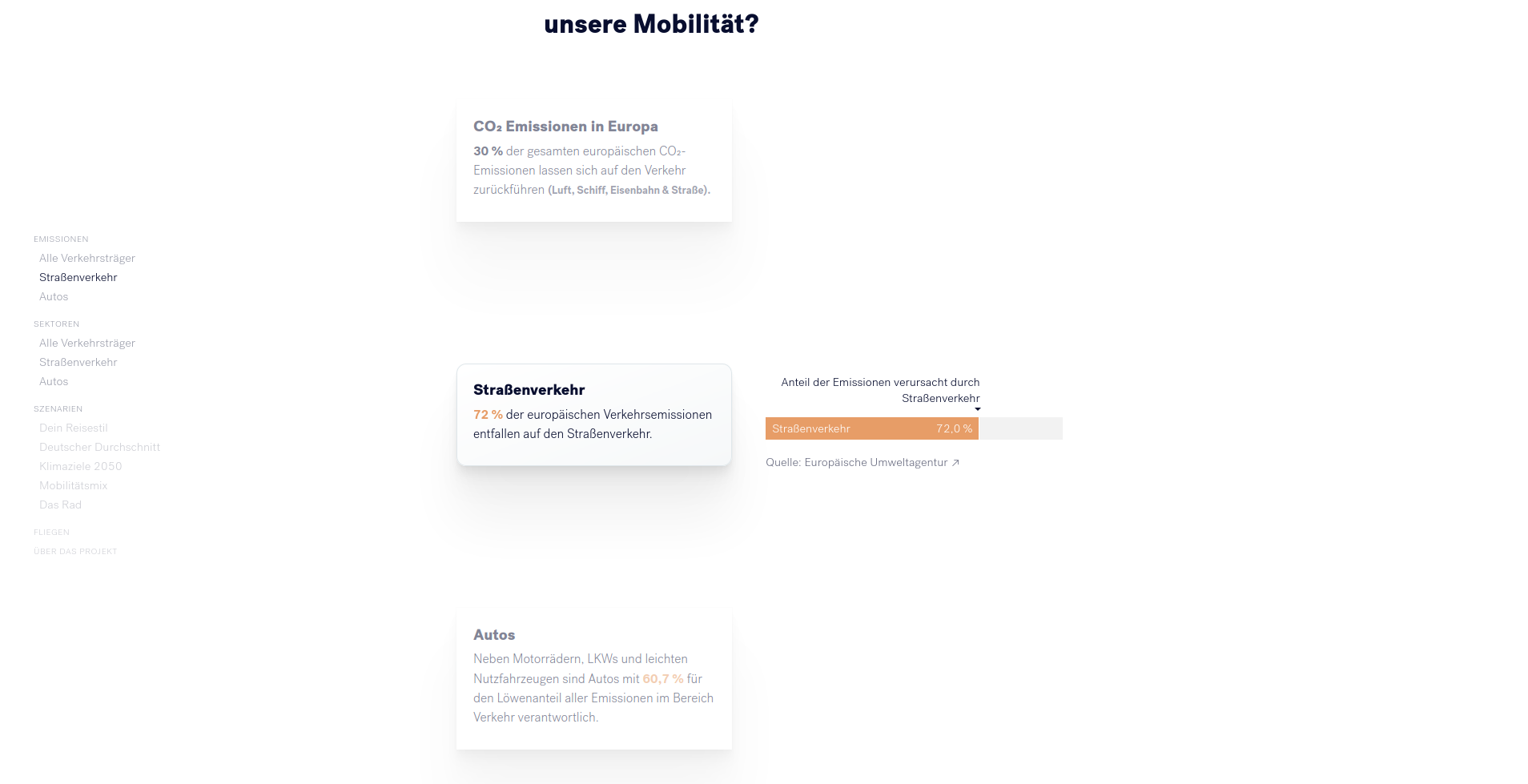
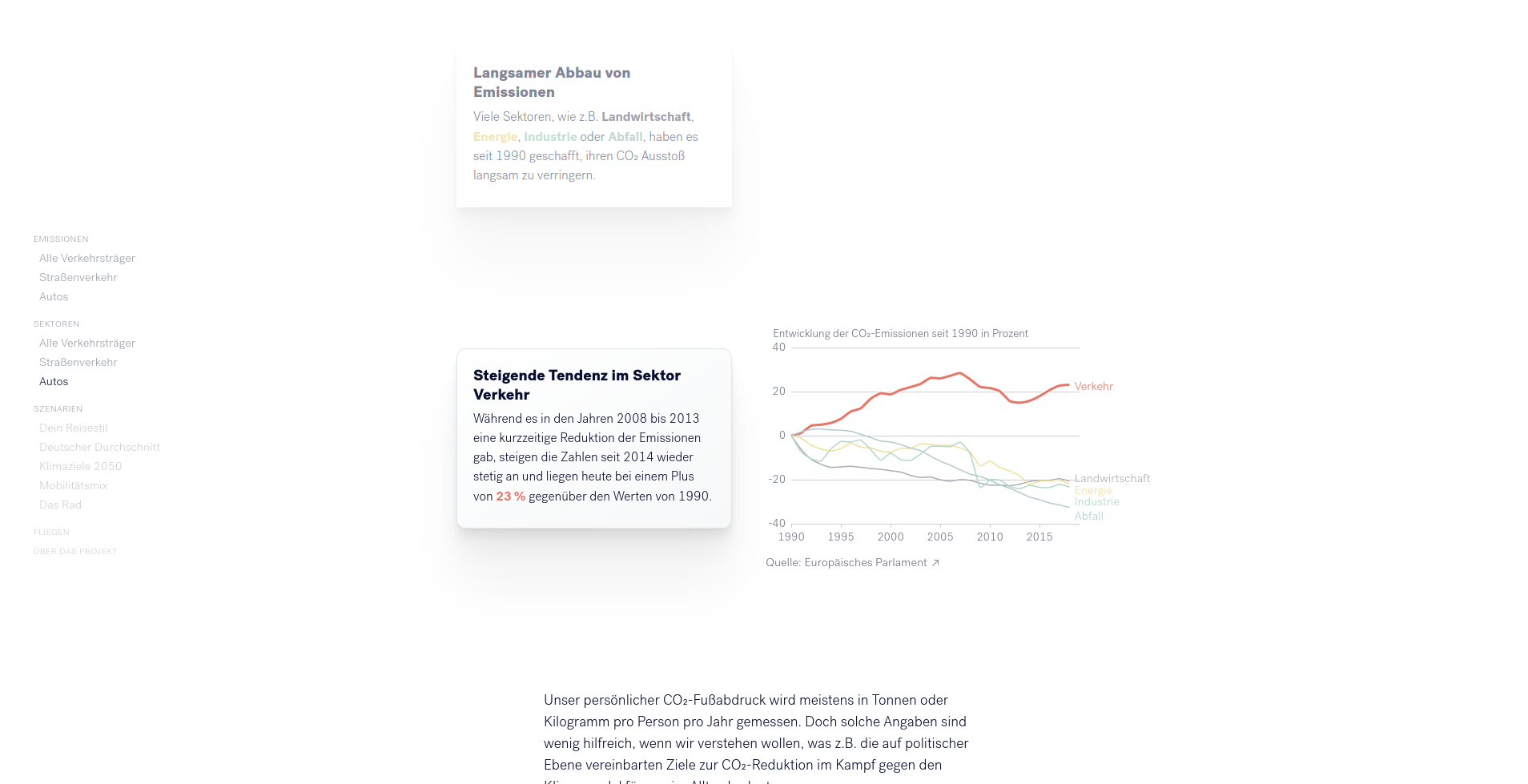
Dieser erste Abschnitt ist noch sehr allgemein gehalten. Als Einstieg in den personalisierten Bereich müssen die Leser*innen ein paar Informationen über sich preisgeben. Diese werden anschließend genutzt, um die Erzählung anzupassen.
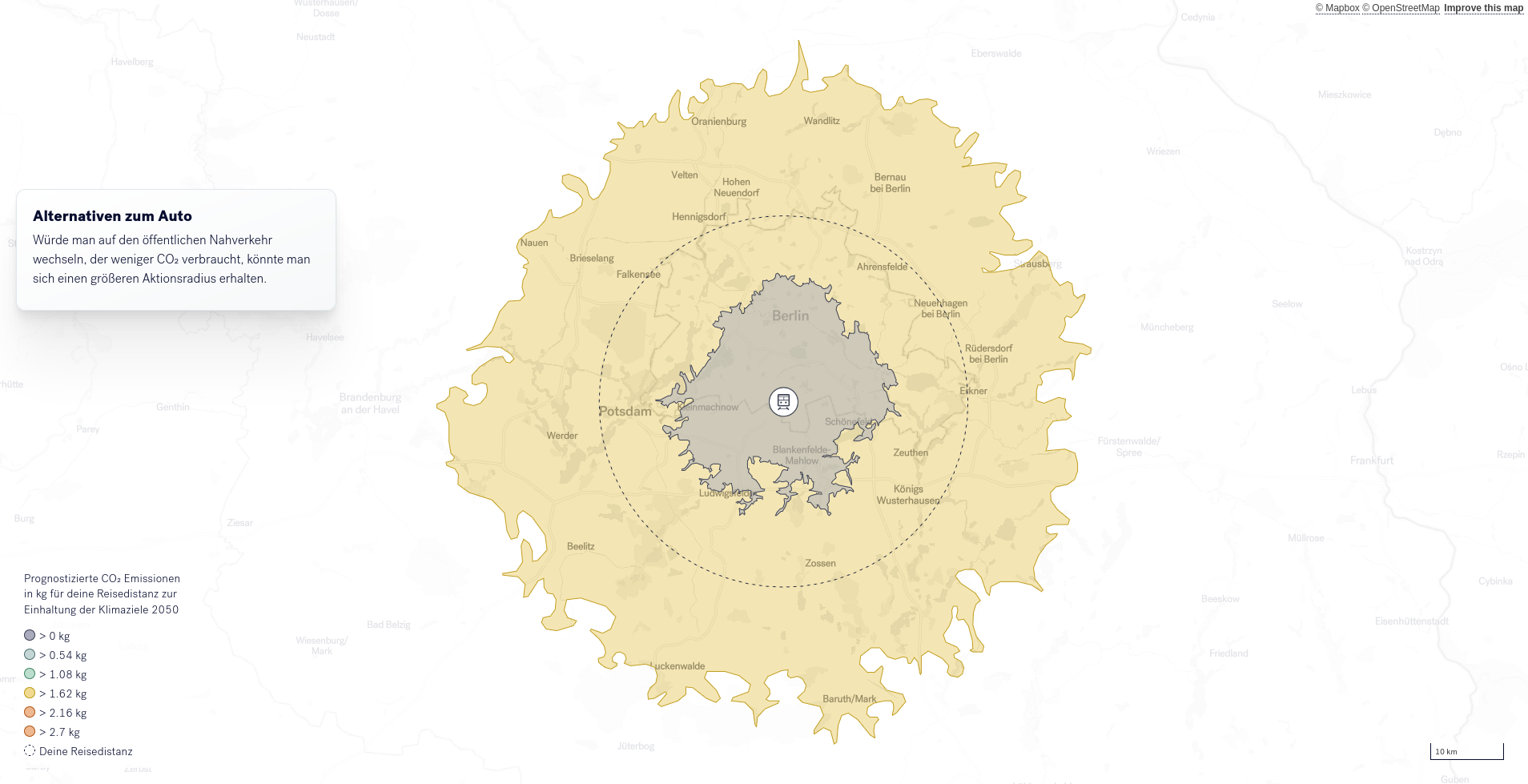
Die personalisierte Erzählung beginnt dann mit einem Wechsel zur von den Nutzer*innen eingegebenen Postleitzahl. Dort wird durch einen Kreis die durchschnittliche tägliche Reisedistanz aufgezeigt, basierend auf dem gewählten Fortbewegungsmittel (basierend auf Mobilität in Tabellen, DLR).
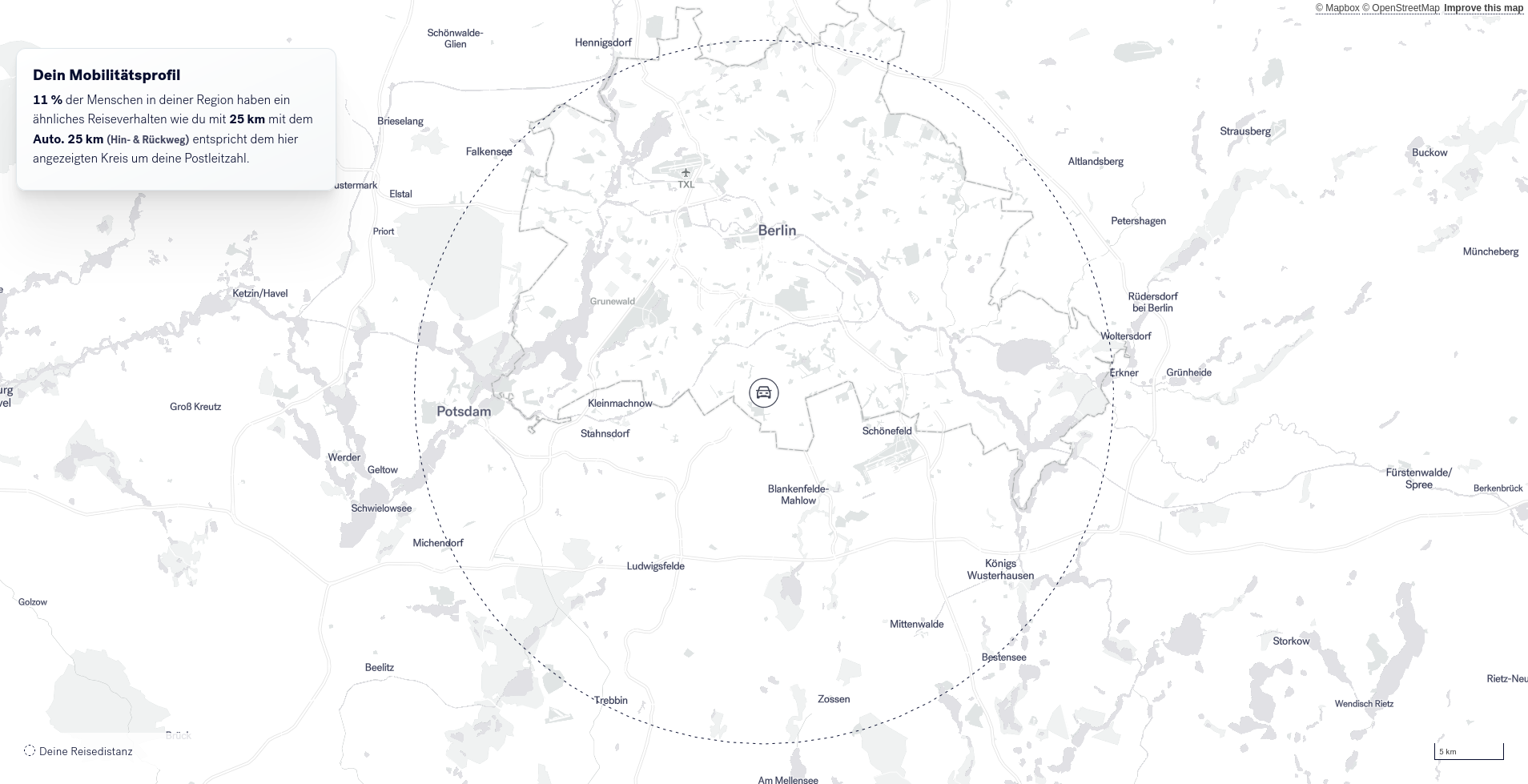
Im nächsten Schritt wird der Durchschnittswert mit der Angabe der Leser*innen kombiniert und erlaubt so ein erstes Reflektieren der eigenen Mobilität im Abgleich mit dem Durchschnitt in der Region. Der Einbezug regionalisierter Durchschnitte ist durchaus relevant, da es regionale Unterschiede im Mobilitätsverhalten gibt, z.B. zwischen ländlichen und städtischen Regionen.
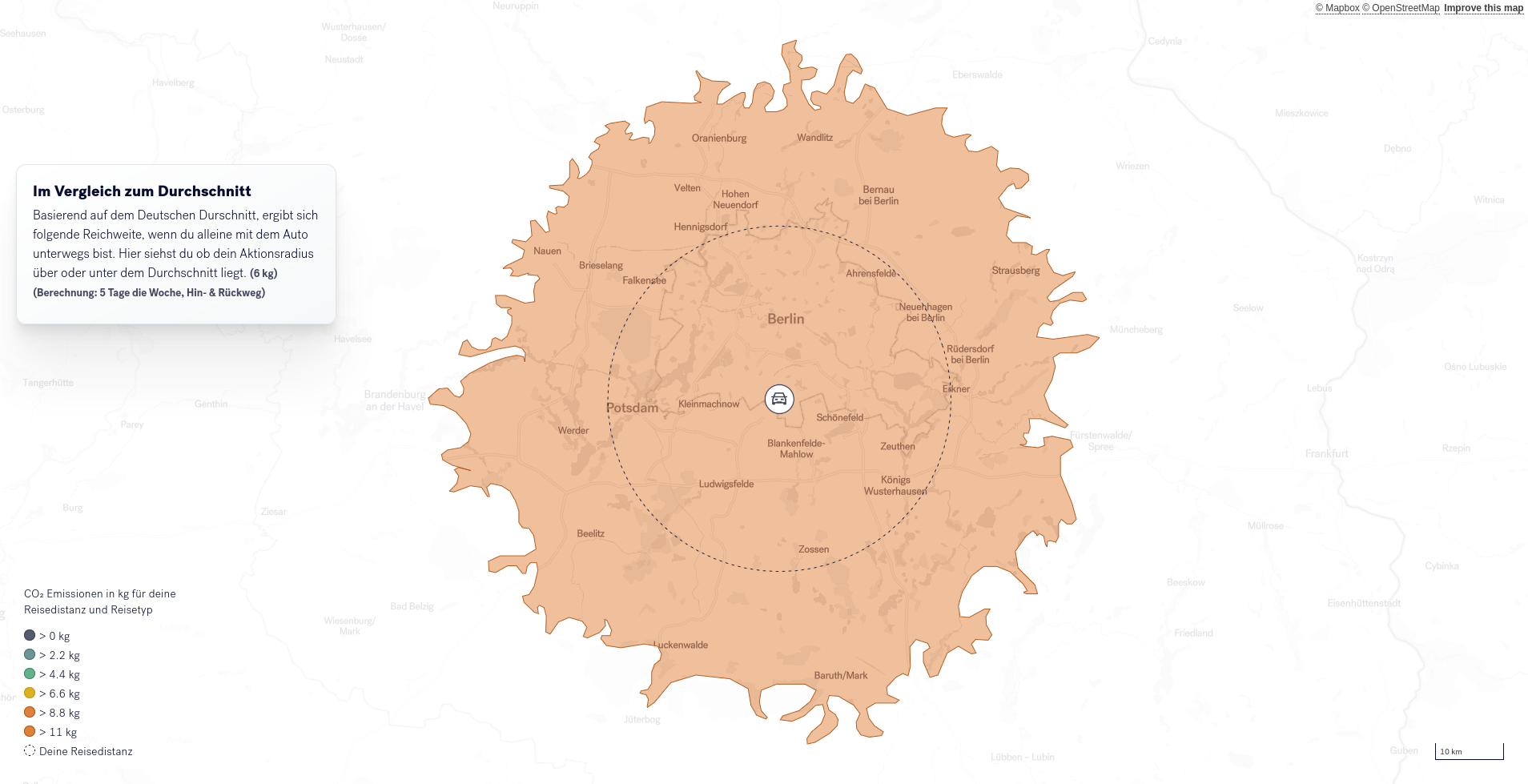
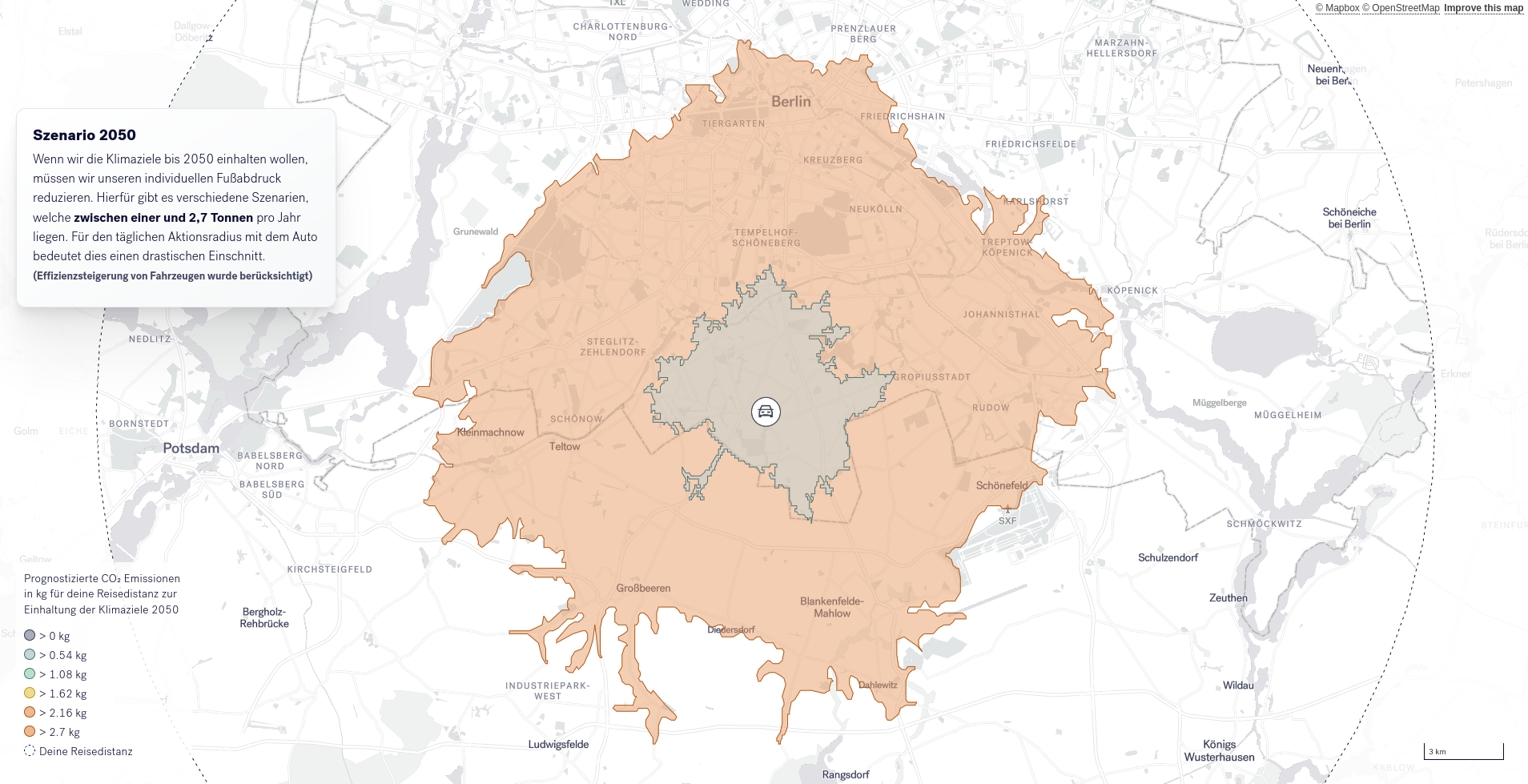
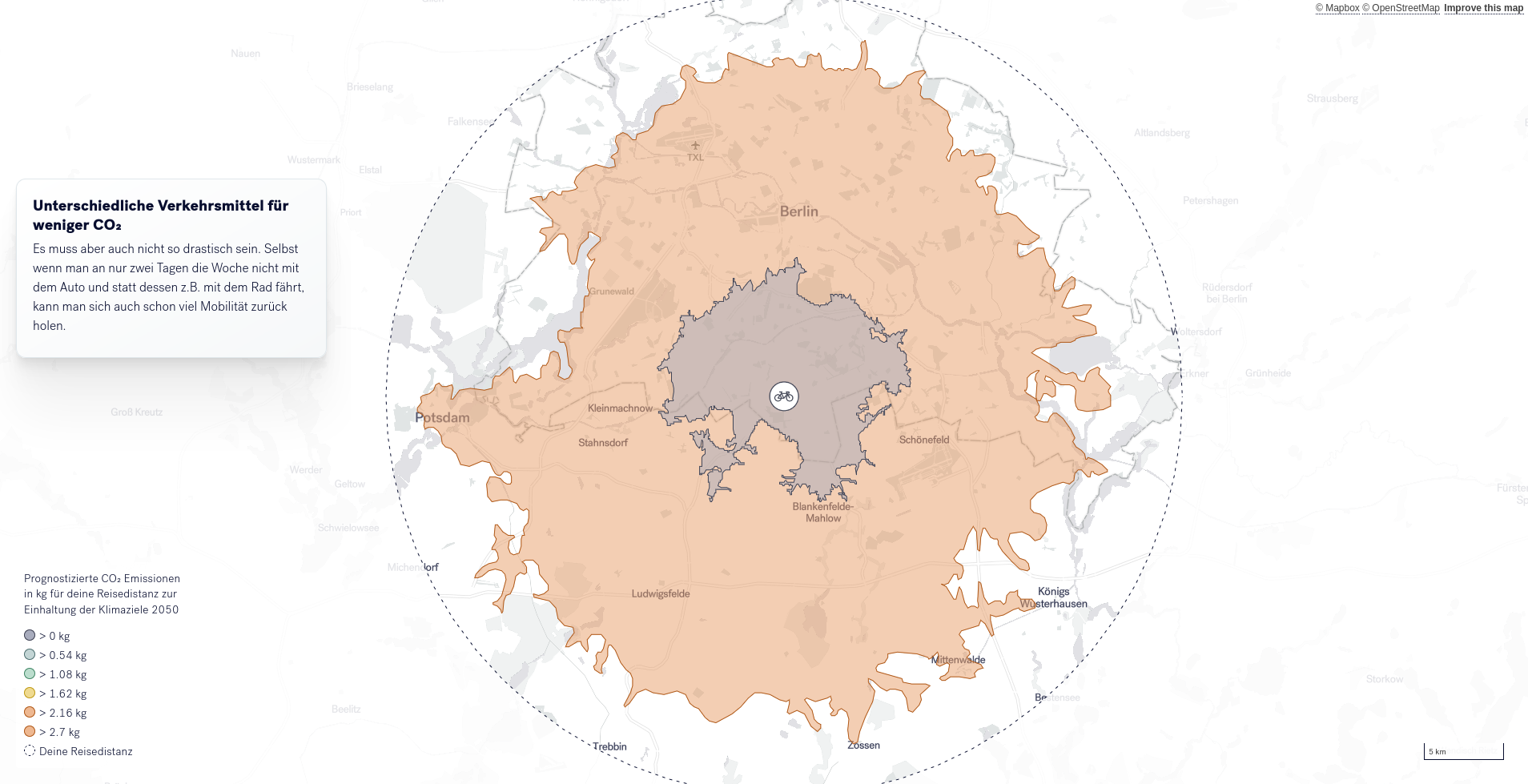
In den darauf folgenden Schritten wird der CO2-Fußabdruck der eigenen Mobilität in den Fokus genommen. Basierend auf Prognosen des Umweltbundesamts werden verschiedene Szenarien eröffnet die anzeigen, wieviel man die eigene Mobilität einschränken müsste, um das für den eigenen CO2-Fußabdruck vorhandene CO2-Kontingent einzuhalten. Um Alternativen aufzuzeigen, werden anschließend unterschiedliche Mobilitätskombinationen aufgezeigt (z.B. ÖPNV+PKW oder ÖPNV+Rad), um so Mobilitätspotentiale aufzuzeigen. Die Art der Kombinationen und Szenarien hängt von der oben getroffenen Auswahl ab.
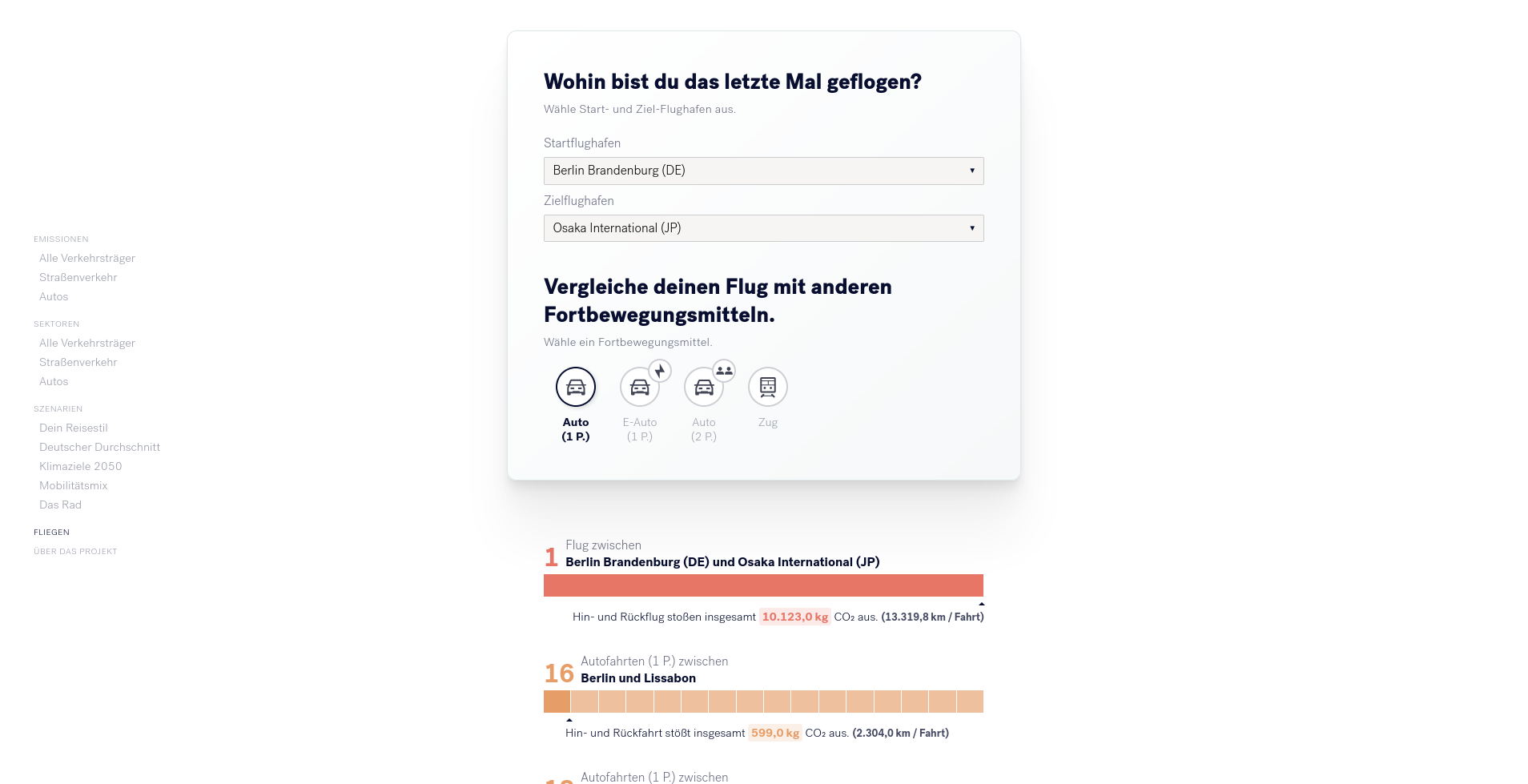
Da Flugreisen so viel CO2 produzieren, dass diese im ersten Teil nicht abgebildet werden konnten, haben wir ein abschließendes Modul entwickelt, welches den nächstgelegenen Flughafen zur angegebenen Postleizahl berechnet und dann CO2-Emissionen für Flugreisen mit anderen Mobilitätsformen für Reisen innerhalbs Europa aufzeigt (z.B. für den Ort Weissach im Tal ist der nächstgelegene Flughafen Suttgart, eine Reise von Stuttgart nach Melbourn entspräche 105 Zugreisen nach Madrid).
Der zweite Prototyp setzt sich mit der Thematik der Klimawandelrisiken in Deutschland auseinander. Wenn man den aktuellen Nachrichten folgt, bekommt man häufig das Gefühl vermittelt, dass der Klimawandel zwar akut ist, aber bisher primär andere Länder betrifft. Dazu zählen Südseeinselns, die vom Meeresanstieg bereits jetzt akut betroffen und bedroht sind oder Waldbrände in Kalifornien oder verheerende Buschfeuer in Australien. Studien des Umweltbundesamts zeigen aber ebenso auf, dass die Folgen des Klimawandels längst auch in Deutschland angekommen sind und in den nächsten Jahren weiter zunehmen werden.
In dieser Storytelling-Anwendungen werden Erkenntnisse des Umweltbundesamts zu Klimawandelrisiken auf den Wohnort der Leser*in heruntergebrochen und lokal visualisiert.

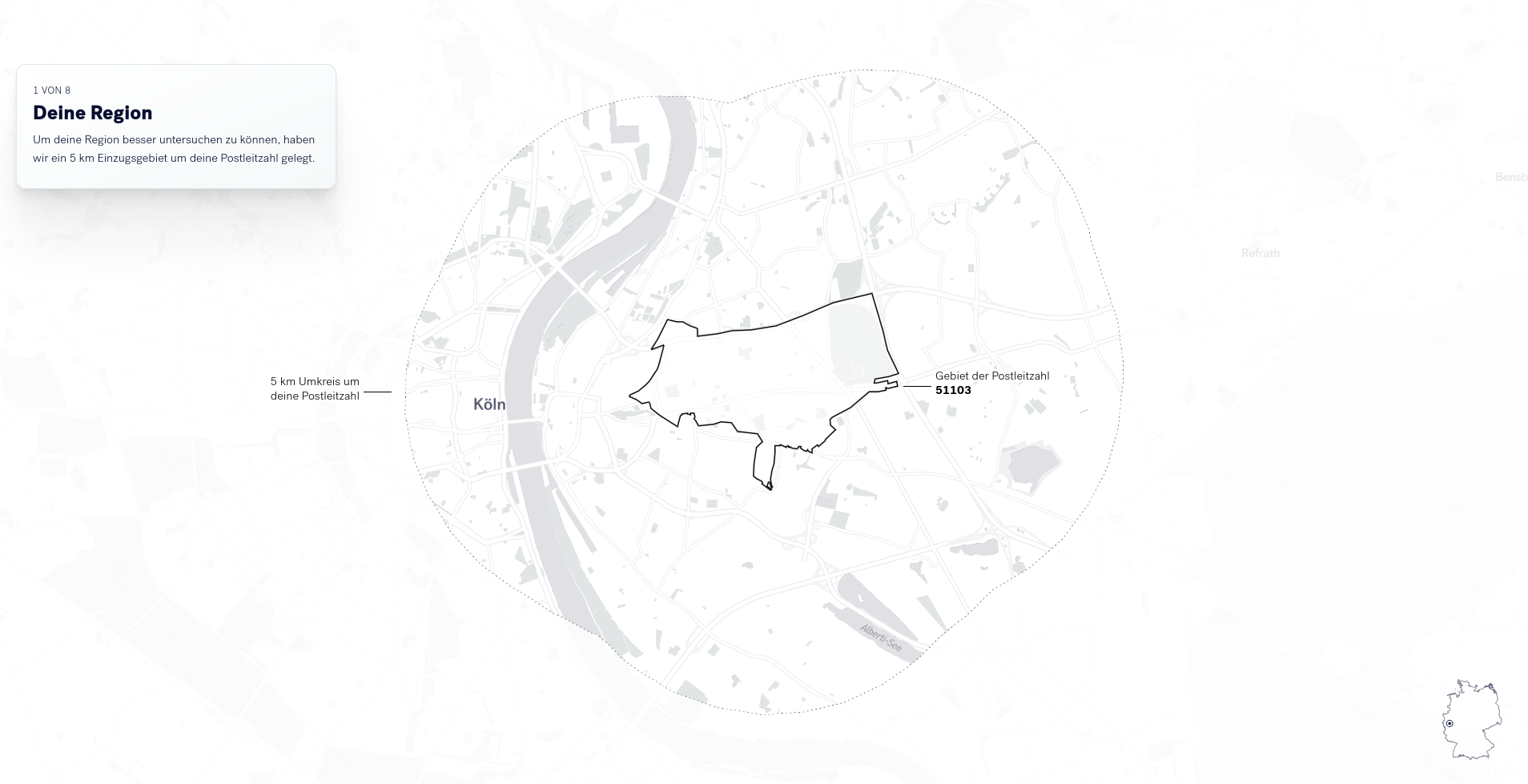
Hierzu beginnt der personalisierte Teil der Anwendung, wie im ersten Prototypen, mit dem eingeben der eigenen Postleitzahl. Daraufhin werden die für diese Postleitzahl notwendigen Daten geladen und dargestellt.

Der eigentliche Storytelling-Abschnitt beginnt mit einer Verortung der Erzählung in der angegebenen Postleitzahl auf einer Karte.
Danach wird erklärt, in welcher Klimazone sich dieses Gebiet befindet. In den nächsten Schritten wird die Bedeutung der Klimazone erklärt. Zukünftige Entwicklungen in Bereichen, die besonders von diesen Auswirkungen betroffen sind - darunter Umwelt, Gesellschaft und Wirtschaft - werden zur Erläuterung herangezogen.
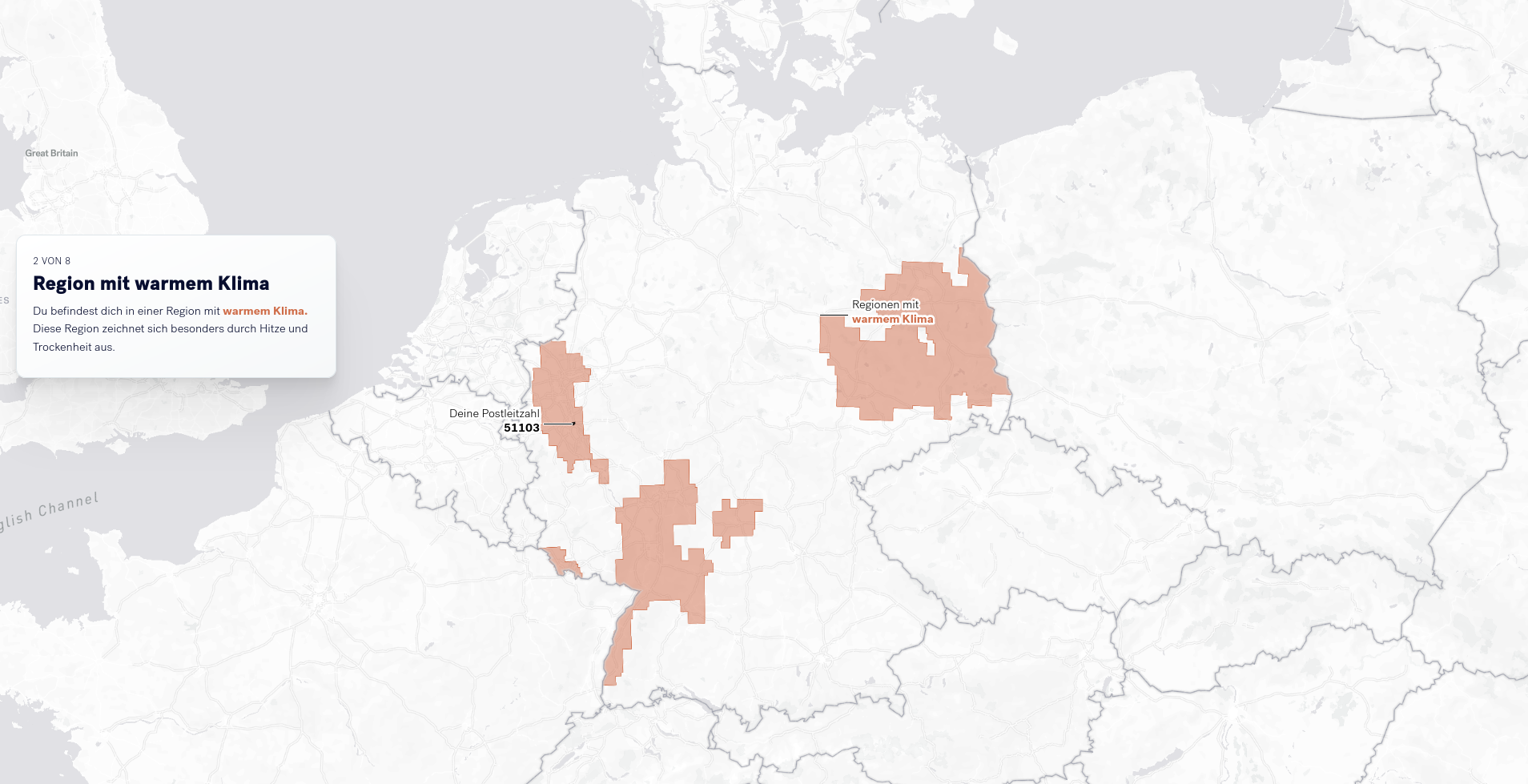
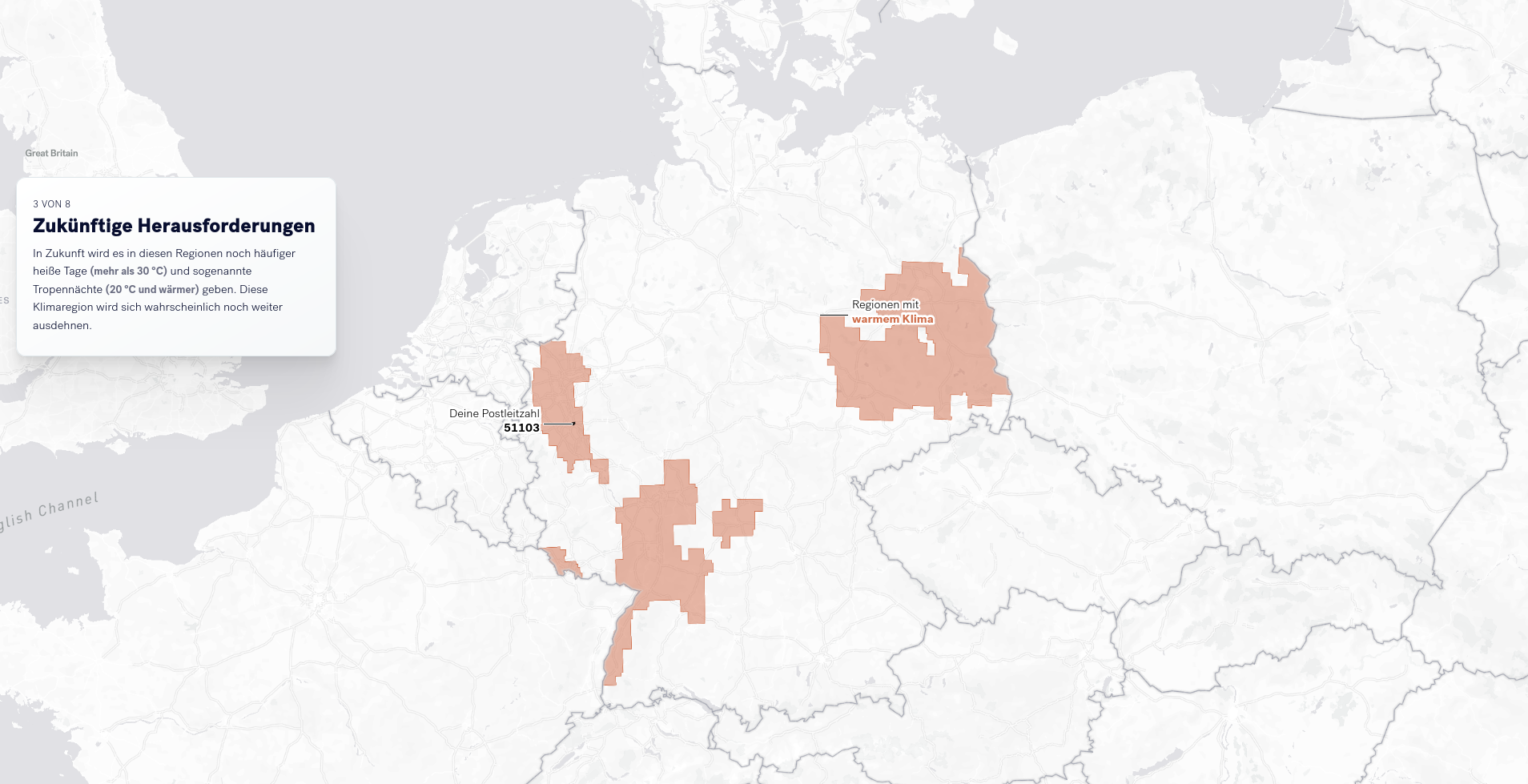
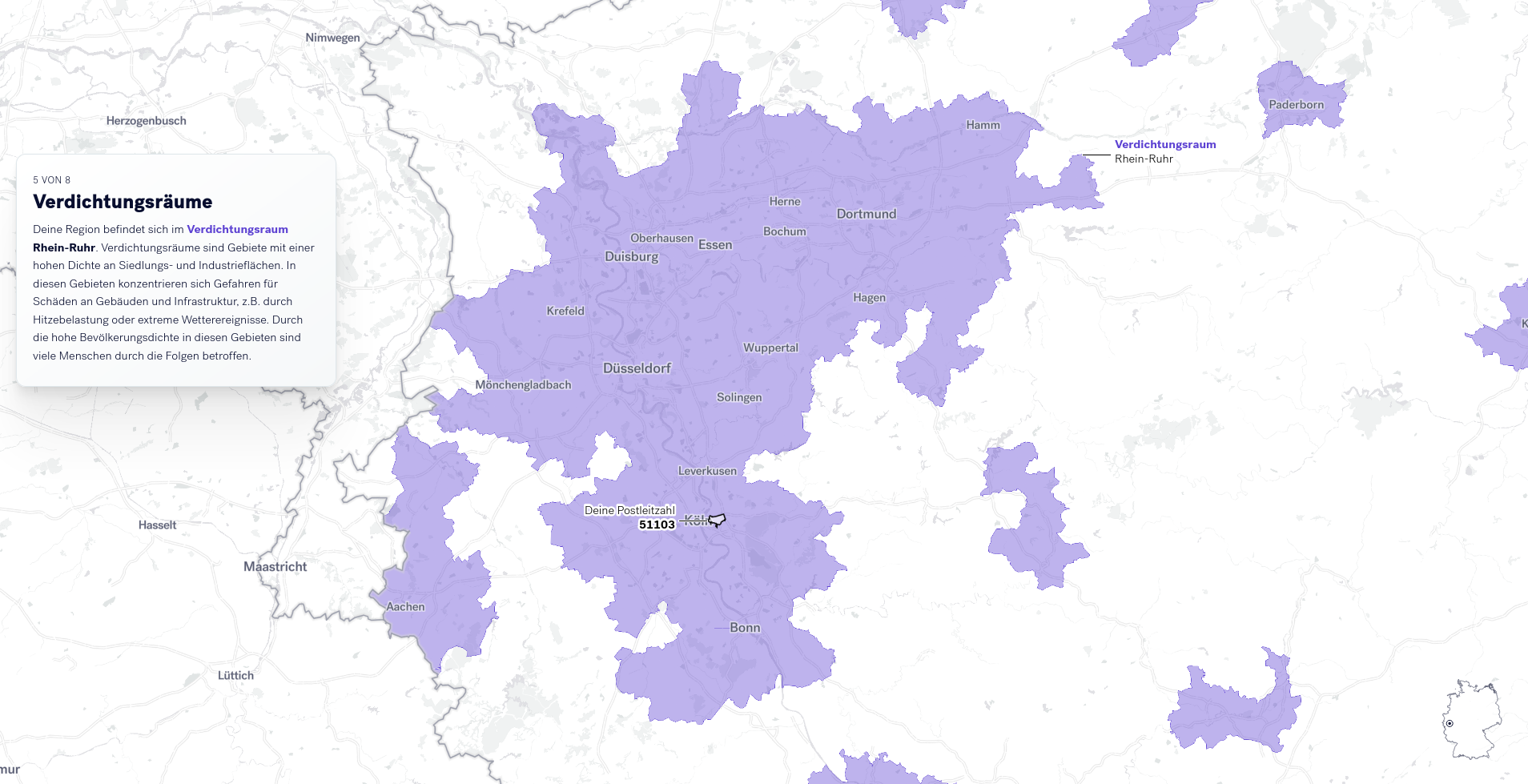
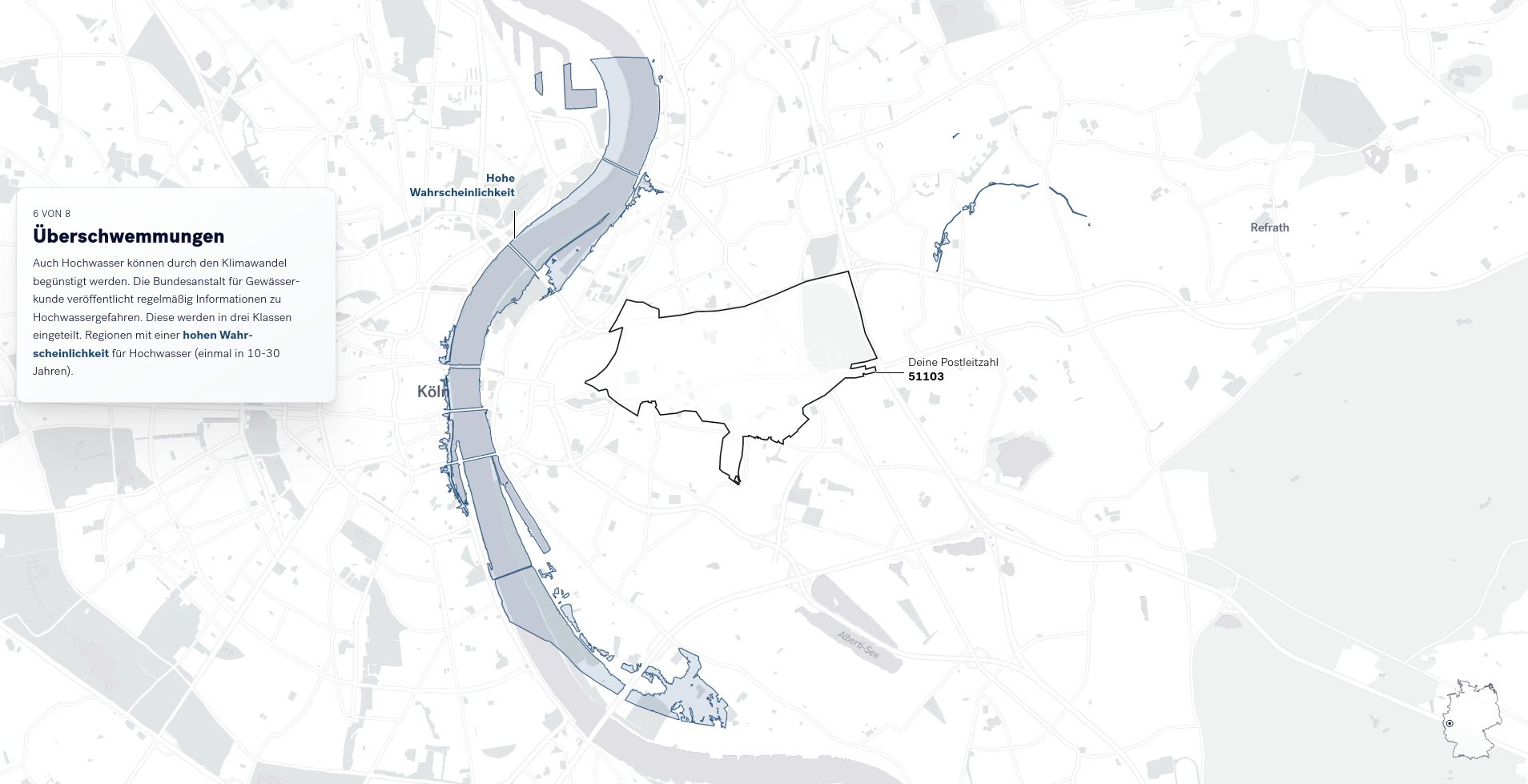
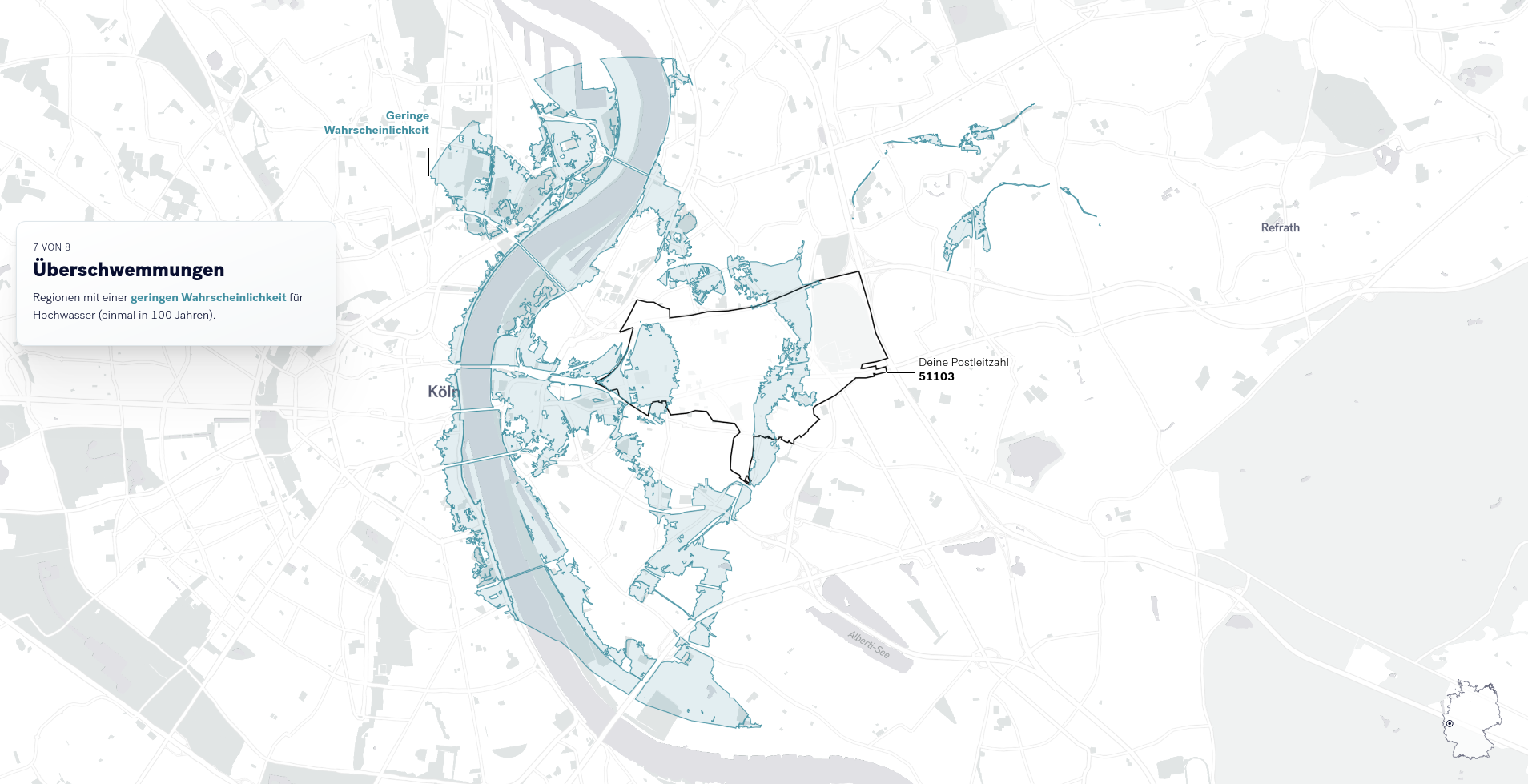
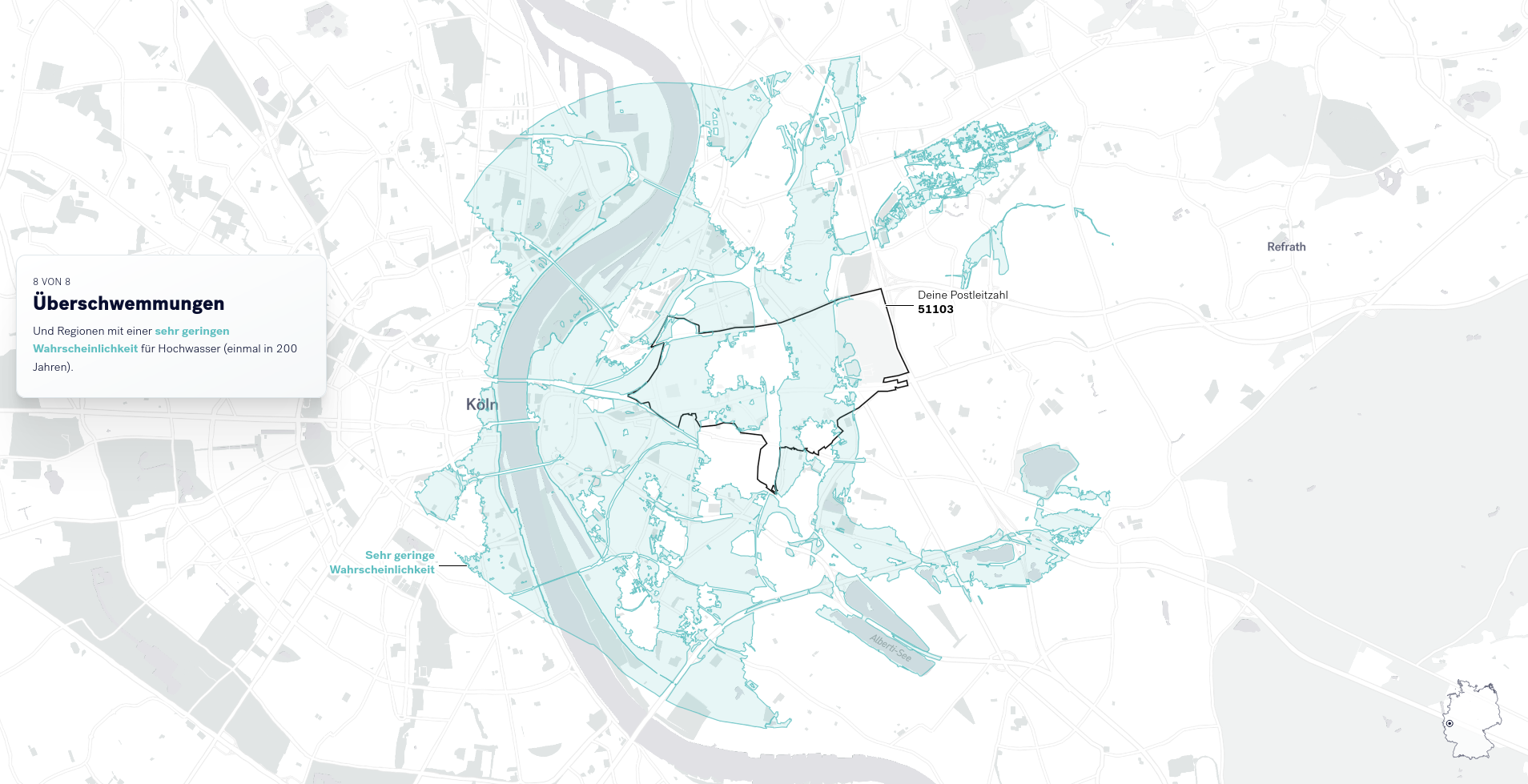
Abhängig von der eingegebenen Postleitzahl werden weitere Risiken mit lokalem Bezug visualisiert. Diese speziellen Risiken betreffen Verdichtungsräume (siehe Abbildung), Gebiete an der Küste mit Sturmflutrisiken, bis hin zu Hochwassern in Flussgebieten (siehe nächster Abschnitt).
Für die Visualisierung der lokalen Hochwassergefahren, wurden Daten der Bundesanstalt für Gewässerkunde genutzt. Hierzu werden den Leser*innen verschiedene Szenarien (Wahrscheinlichkeiten) für Hochwasser aufgezeigt.
Um die zeitliche Entwicklung deutlich zu machen, werden zum Abschluss des personalisierten Bereichs die Entwicklungen der lokalen Durchschnittstemperaturen mit den Entwicklungen der Temperaturen in ganz Deutschland verglichen. Hierbei werden der deutliche Anstieg der Temperaturen unabhängig von möglicherweise lokal abweichenden Phänomenen hervorgehoben.
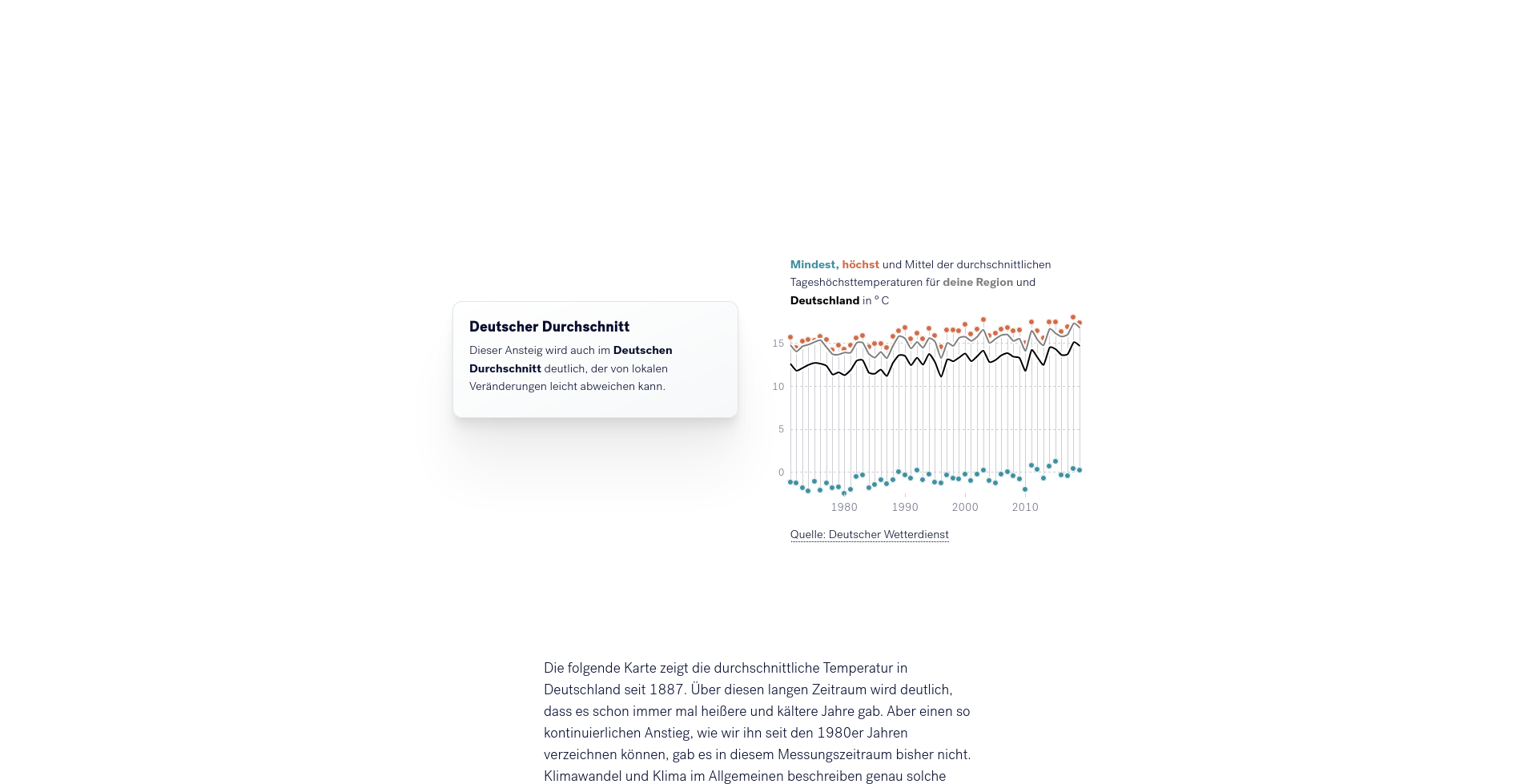
Der Vergleich zwischen den lokalen und nationalen Temperaturtrends schafft den Bezug zwicher der lokalen und nationalen Ebene. Dies schließt den letzten Abschnitt der Anwendung ab, indem auf einer Deutschlandkarte die Entwicklung der Temperaturen der letzten 100 Jahre abgebildet werden.
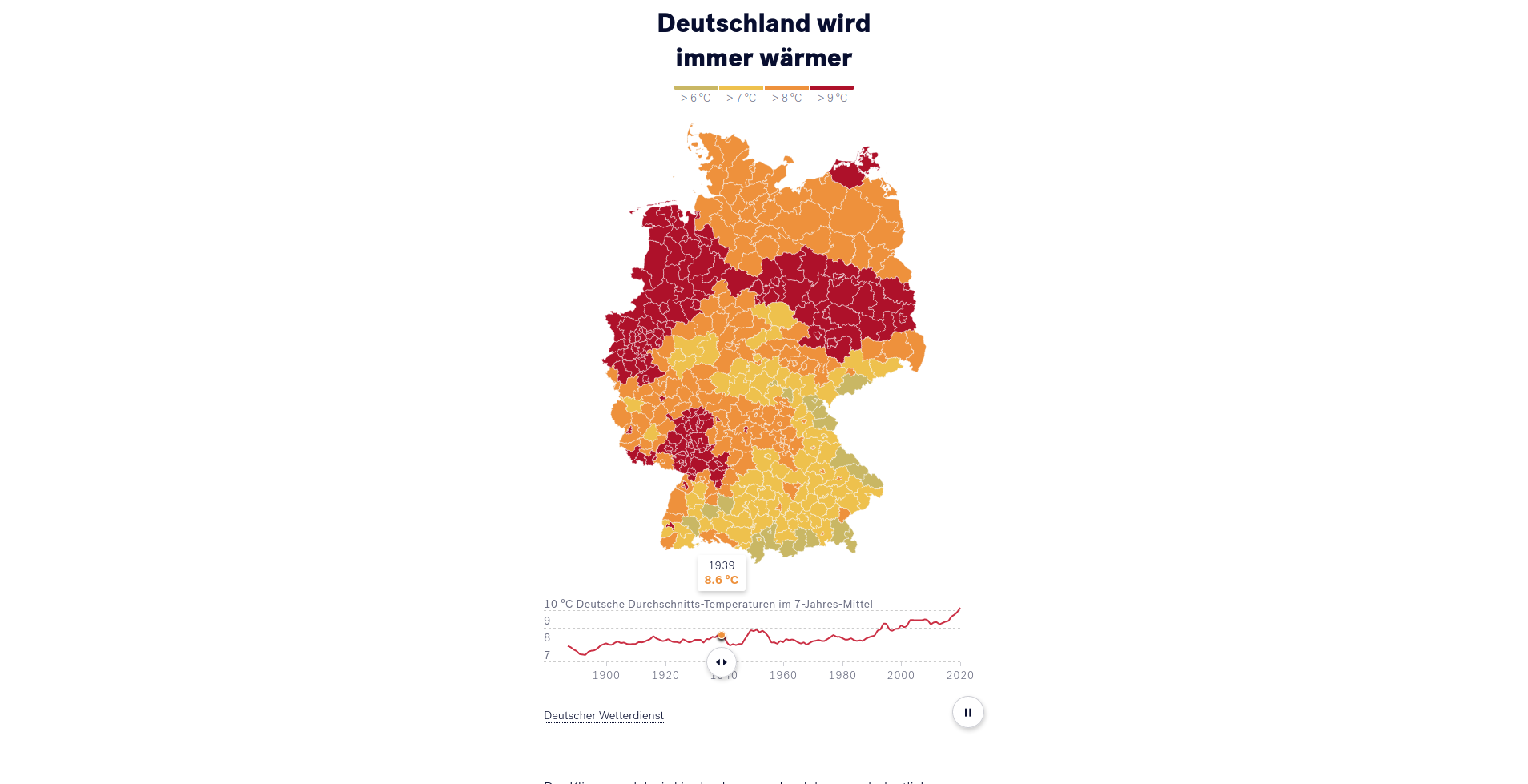
Für Leser*innen, die sich weiter mit der Materie auseinandersetzen wollen, werden zum Abschluss der Anwendungen noch Leseempfehlungen gegeben. Diese Empfehlungen sind auch in Abhängigkeit von den Angaben der Leser*innen personalisiert, sodass Themen für die Region der Leser*in besonders hervorgehoben werden.

Die technische Dokumentation gliedert sich in zwei Abschnitte. Der erste Anschnitt bezieht sich auf die Umfrage-Plattform und alle dazugehörigen Komponenten und der zweite Abschnitt behandelt die beiden Prototypen zur datengestützten Wissenschaftsvermittlung. Die hier vorliegende Dokumentation gibt eine Übersicht über die verschiedenen entwickelten Komponenten. Eine detailliertere und stärker technisch fokussierte Dokumentation befindet sich in den einzelnen Code-Repositorien, welche hier verlinkt werden. Diese detaillierten technischen Dokumentationen sind in englische Sprache verfasst, um eine möglichste breite Nachnutzbarkeit der einzelnen open-source Komponenten sicherzustellen.
Obwohl sich viele der Komponenten kurz vor einem Release-State befinden, muss hier deutlich unterstrichen werden, dass es sich bei den entwickelten Prototypen nicht um Release-Candidates handelt. Ziel des Vorhabens LoCobSS war es vielmehr, Ideen und Möglichkeiten für den hier vorliegenden Anwendungsfall aufzuzeigen. Um sich hierbei möglichst realistischen Umsetzungsoptionen anzunähern und gleichzeitig erste Grundlagen für eine spätere Implementierung zu schaffen, wurden diverse Komponenten und Prototypen entwickelt. Um diese zu release-fähigen Produkten weiterzuentwickeln, sollten vor allem folgenden Punkte bearbeitet werden:
In der aktuellen Version wurden die Services und Komponenten für die Google-Cloud-Infrastruktur optimiert. Die meisten Komponenten sind aber völlig plattform-unabhängig. Die einzigen Komponenten, die sich nicht ganz so leicht anpassen lassen, sind alle Komponenten rund um die Nutzer*innenverwaltung. Da selbige nicht im Fokus der prototypischen Entwicklung lagen, haben wir Googles Firebase Ökosystem genutzt, um möglichst unkompliziert eine Verwaltung von Nutzer*innen implementieren zu können.
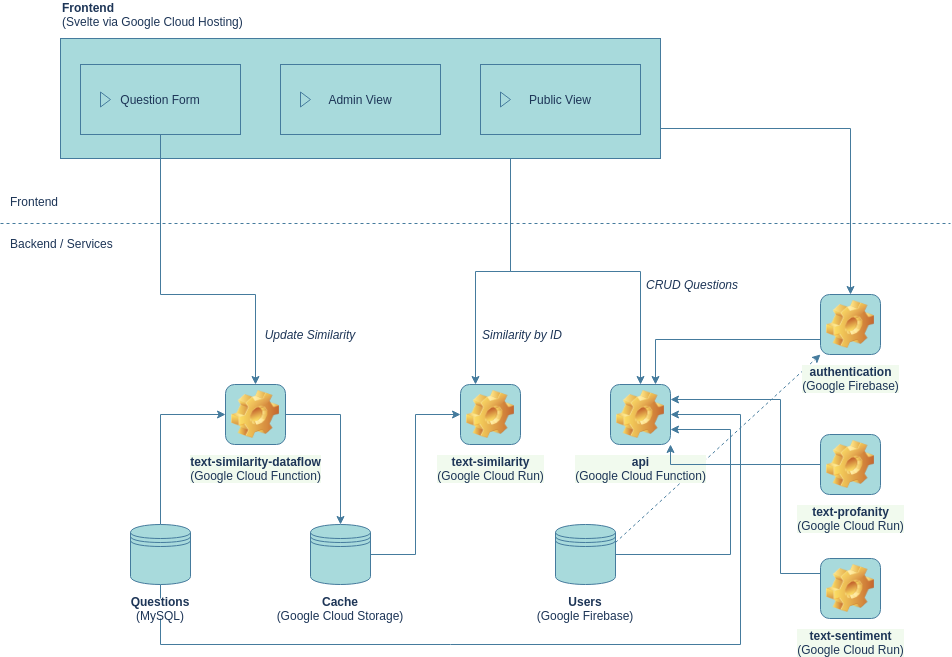
Das Frontend, in der alle Komponenten für die Umfrage zusammenfließen, ist im LoCobSS-platform Repository zusammengeführt. Es handelt sich hierbei um eine sogenannte Single Page Application (SPA), welche mit dem Framework SVELTE entwickelt wurde. Die Anwendung lässt sich grob in drei Hauptbereiche unterteilen: 1) Öffentlicher Bereich zum Durchstöbern der Fragen und zum Fragen stellen, 2) Interner Bereich für Bürger*innen zur Verwaltung der eigenen Daten und zur Verfolgung von Fragen, sowie 3) der Bereich für Redakteur*innen zum Verwalten der Fragen und Nutzer*innen.
Repo: LoCobSS-platform
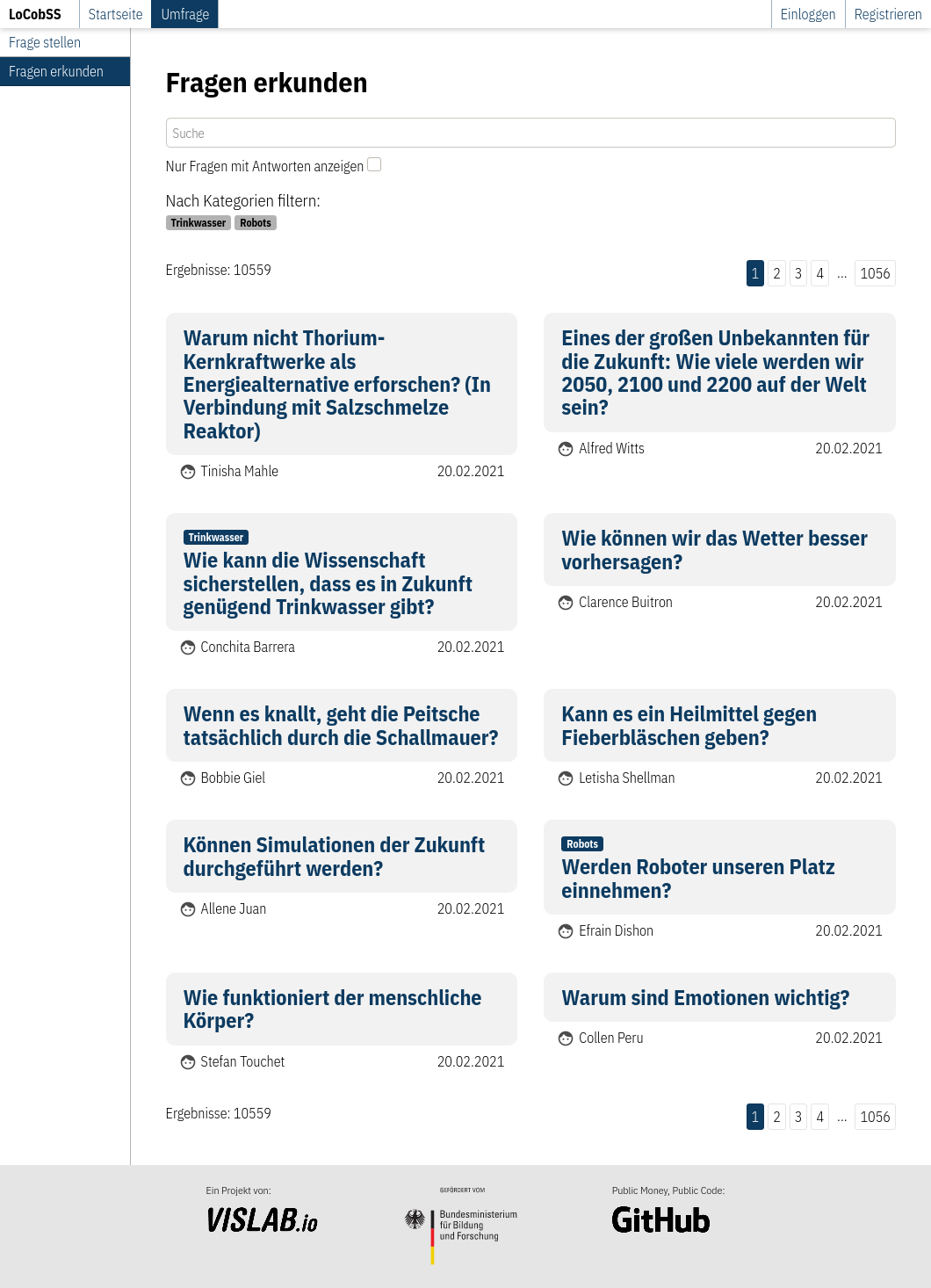
Öffentlicher Bereich
Nutzer*innen können die von anderen Teilnehmer*innen erstellten Inhalte auf der Plattform im öffentlichen Bereich explorieren. Inhalte können nach Taxonomien, Datum und Suchbegriffen gefiltert werden sowie danach, ob es schon eine Antwort für die Frage gibt. Daten werden über die API bereitgestellt.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/list.svelte
API: /public/questions
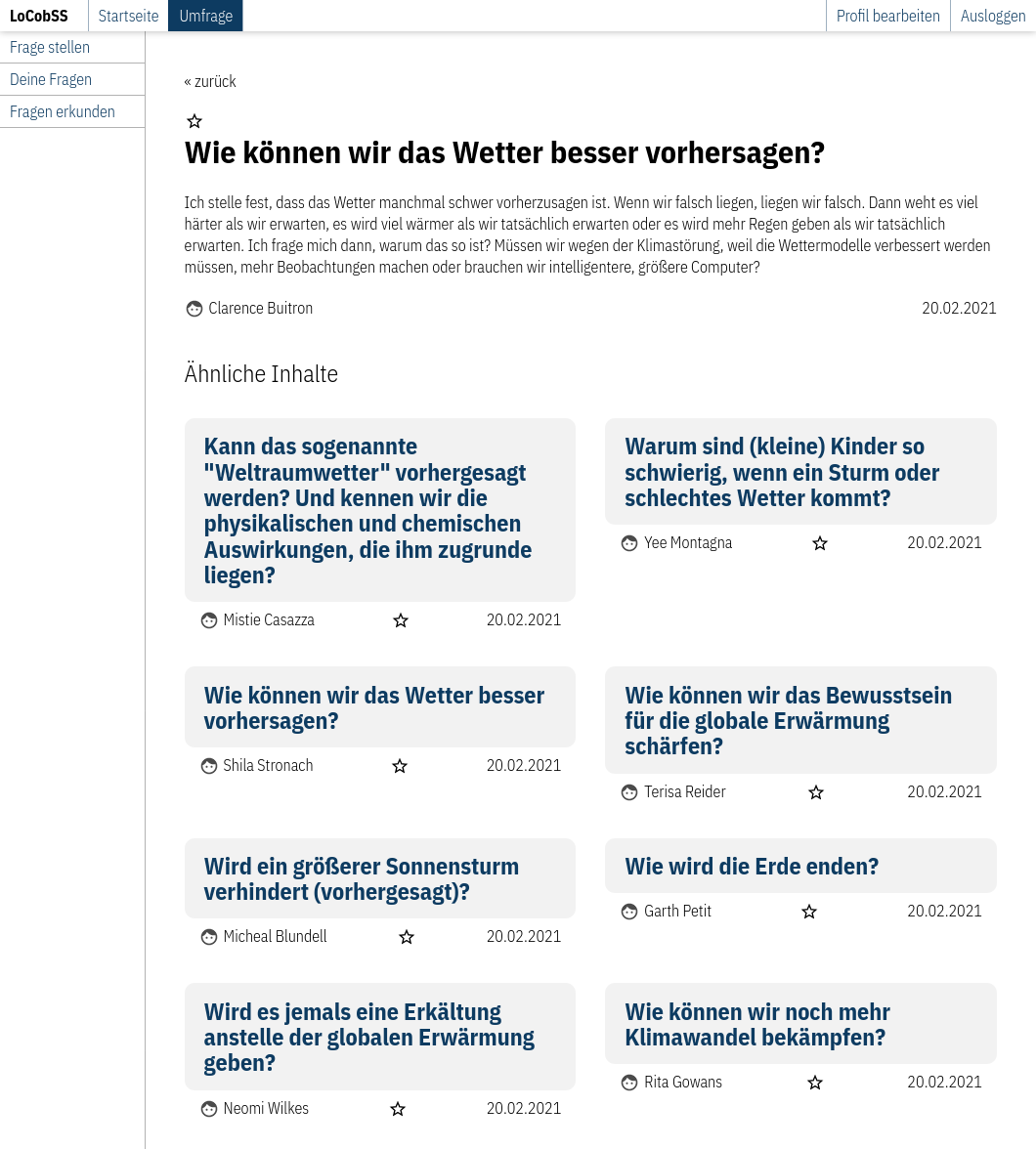
Zu jeder Frage gibt es auch eine Detailansicht. Neben weiteren Details zur Frage werden hier auch ähnliche Fragen angezeigt. Diese werden über die API abgerufen, welche dafür den similarity-Service nutzt.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/details.svelte
API: /public/questions/:id
Das Formular zum Erfassen der Fragen nutzt Client-Side Classification zur Erfassung von Regiostar-5-Gebieten (siehe 2.4). Das Recaptcha-Verfahren11 schützt die Seite.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/ask.svelte
API: /question/create
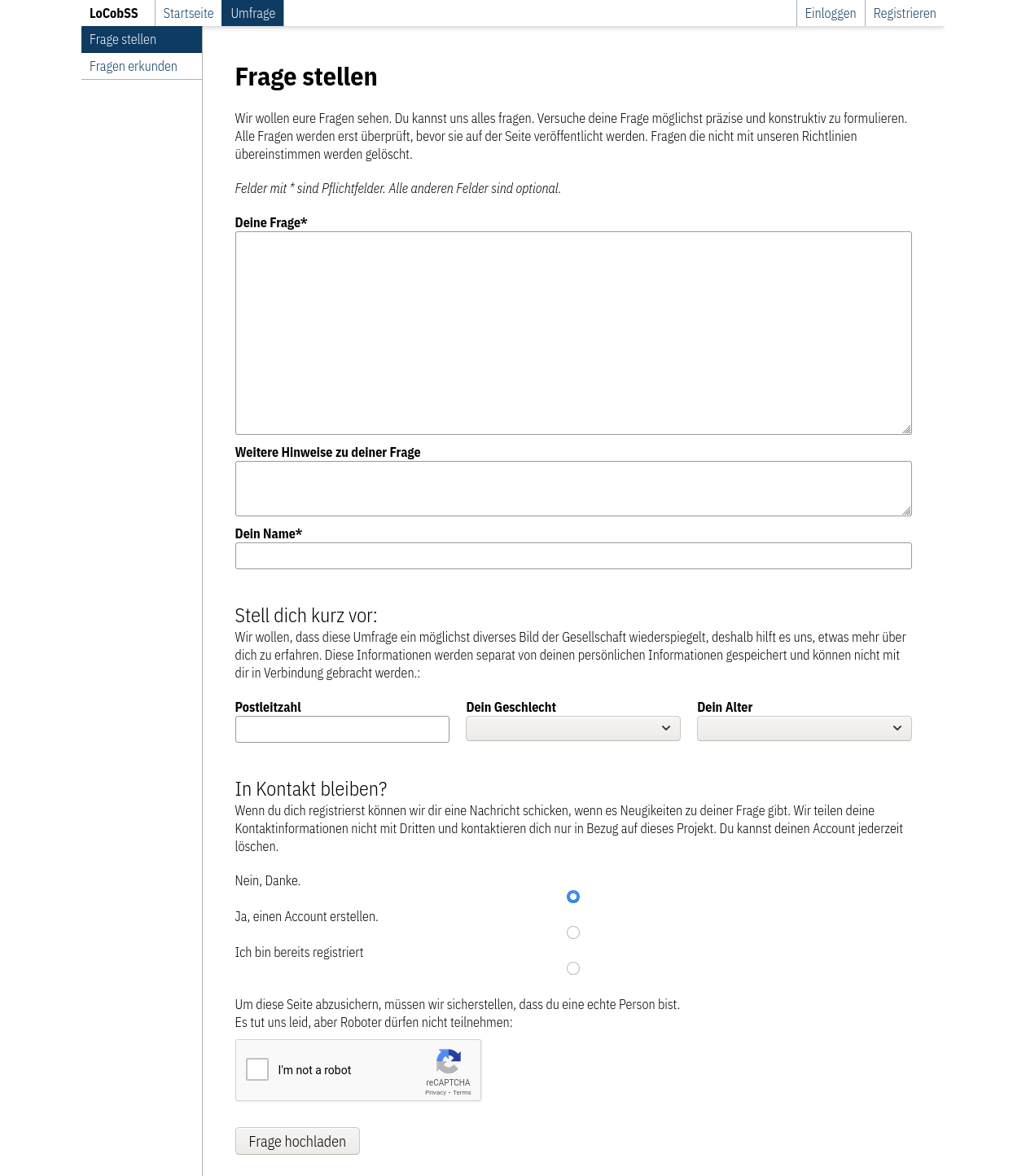
Die abgeschickten Fragen werden auf Profanität hin überprüft, eine Sentiment-Analyse wird durchgeführt, sowie Ähnlichkeiten zu Beiträgen anderer Bürger*innen werden berechnet. Fragedaten und statistische Daten werden unabhängig gespeichert. Danach werden ähnliche Fragen angezeigt, welche die Benutzer*in dann ranken kann (siehe Kapitel 3.3.4).
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/ask.svelte
API: /question/link
Benutzer*innen können sich registrieren, während sie eine Frage stellen, oder unabhängig davon.
Router: src/lib/routes/user.ts
View: src/views/pages/user/register.svelte
Durch den Login bekommen Nutzer*innen die Möglichkeit, Fragen zu markieren (like) und ihre eigenen Fragen zu verfolgen.
Router: src/lib/routes/user.ts
View: src/views/pages/user/login.svelte
In der persönlichen Liste werden die eigenen Fragen und markierten Inhalte übersichtlich zusammengeführt.
Router: src/lib/routes/survey.ts
View: src/views/pages/survey/mylist.svelte
API: /user/questions
API: /user/question/like/:id
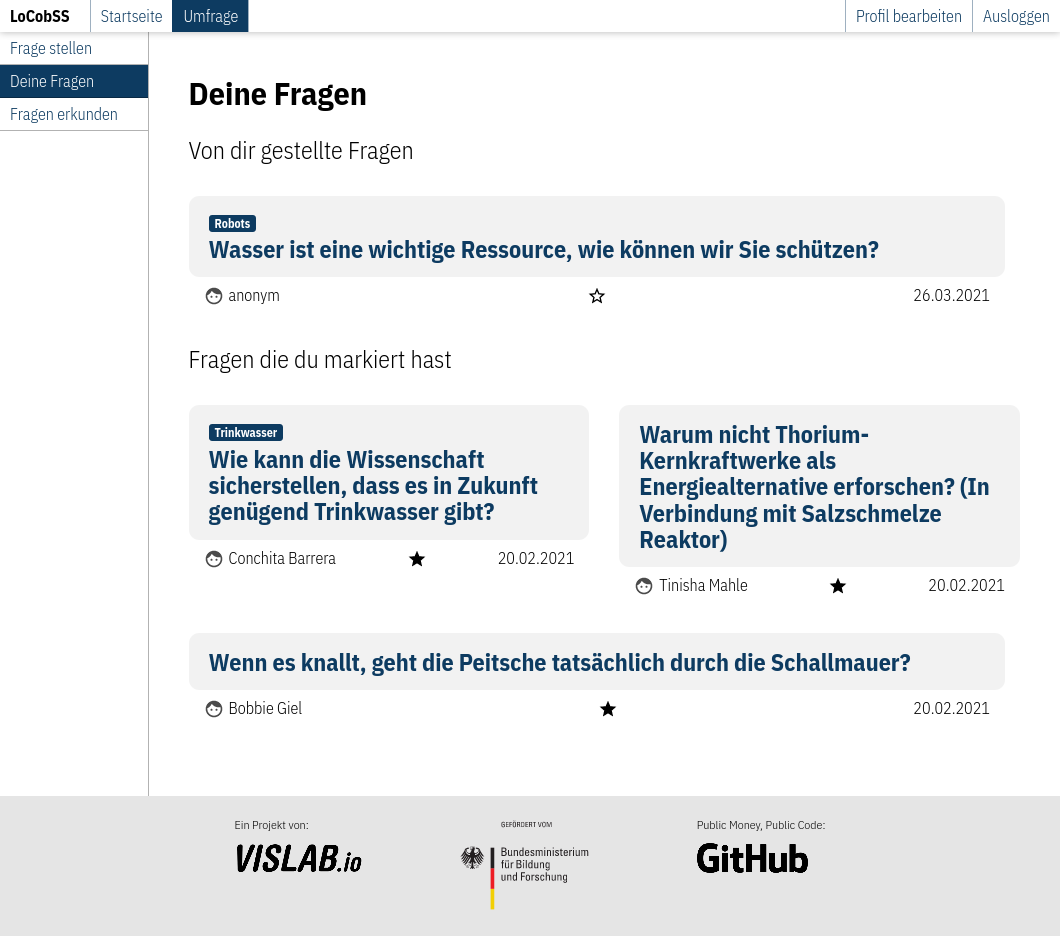
Die Administrationsansicht ist etwas funktionaler gestaltet. Von hier aus können Fragen schnell gelöscht, bearbeitet und kategorisiert werden.
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/questions/list.svelte
API: /questions
API: /question/delete/:id
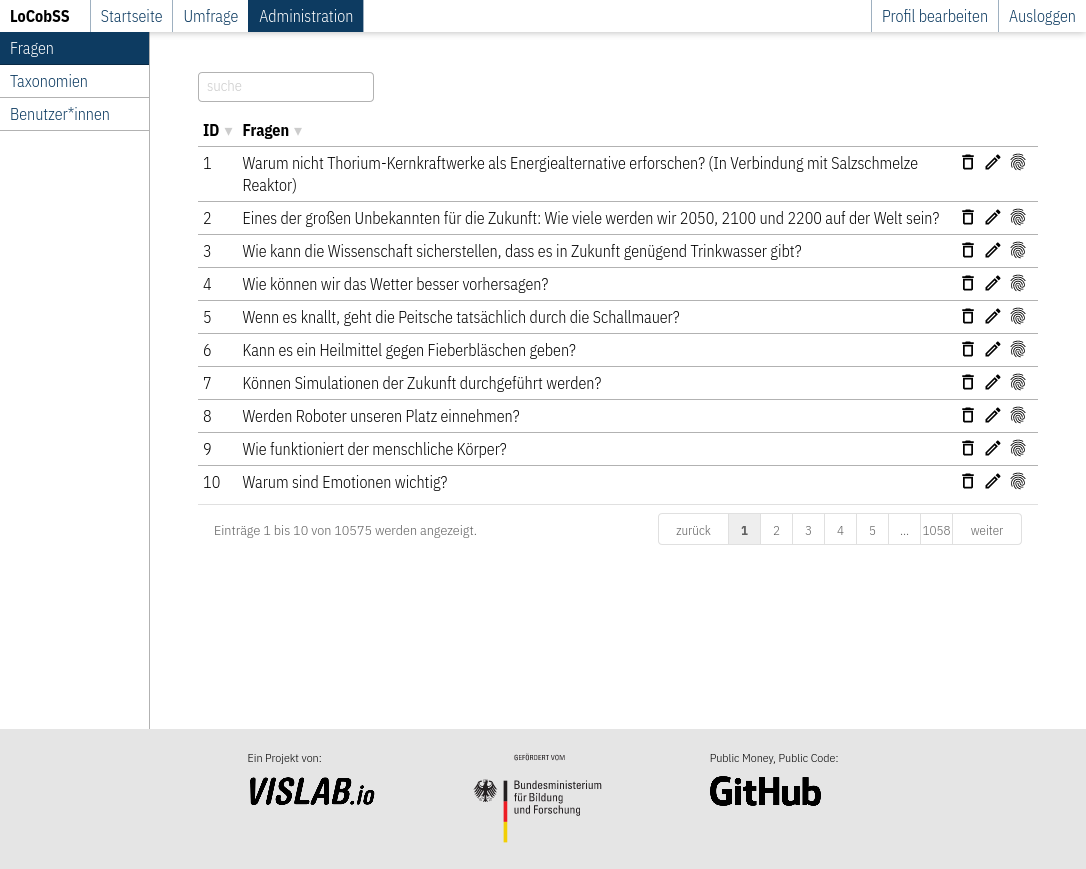
Über die Bearbeitungsansicht kann der Status der Fragen verändert werden (nur auf “veröffentlicht” gestellte Fragen, tauchen im öffentlichen Bereich auf), Zuordnungen zu Kategorien oder Antworten gemacht werden, sowie Textänderungen an den Fragen vorgenommen werden. Als zusätzliche Informationen werden die Ergebnisse der Sentiment- und Profanitäts-Analyse angezeigt.
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/questions/edit.svelte
API: /question/update/:id
In der Clusteransicht können Fragen inhaltlich in gemeinsame Taxonomien überführt werden. Siehe hierzu auch Kapitel 3.3.3
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/questions/cluster.svelte
API: /related/questions/cluster | /public/taxonomies | /taxonomy/assign | /taxonomy/create

Die über das Clustering erstellen Kategorien können später über die entsprechende Seite auch nachträglich bearbeitet werden.
Router: src/lib/routes/admin.ts
View: src/views/pages/admin/taxonomy/list.svelte
API: /public/taxonomies
API: /taxonomy/delete/:id
Die datengestützten Storytelling-Anwendungen sind ebenfalls in SVELTE entwickelt worden. Zu den Konzepten zur Personalisierung siehe Kapitel 4.1ff und zu den Inhalten der beiden Anwendungen siehe Kapitel 4.4 und 4.5. Im Folgenden geben wir einen kurzen Einblick in die datenwissenschaftlichen Arbeiten hinter den Anwendungen.
Das Herz der Mobilitätsanwendung ist eine spezielle Routing-Engine zur Berechnung von CO2-Produktion auf bestimmten Strecken. Hierzu haben wir die Valhalla Routing Engine so modifiziert, dass statt dem Parameter Zeit nun CO2-Ausstoß zur Berechnung genutzt wird. Diese spezielle Version haben wir ebenfalls öffentlich zugänglich gemacht. Hierzu mussten wir erst CO2-Modelle generieren. Anschließend haben wir für die verschiedenen Mobilitätsprofile und Postleitzahlen statische Datenexports generiert, um eine möglichst performante Anwendung zu erzielen.
Der Code zur Anwendung ist auf GitHub zu finden.
Die Personalisierung der Klimawandelrisiken ist nicht so komplex wie bei der Mobilitätsanwendung, dafür werden allerdings mehr Daten einbezogen. Daten zu Klimazonen, Verdichtungsgebieten und Überschwemmungen wurden für alle Postleitzahlen vorberechnet und als statische Datenexports bereitgestellt. Dasselbe wurde auch für die Klima- und Wetterdaten des Deutschen Wetterdienstes (DWD) gemacht, um die Graphen im letzten Abschnitt der Anwendung zu generieren.
Der Code zur Anwendung ist auf GitHub zu finden.